C++¶
我会试图跟着 CS106 这门课的节奏走。课程链接:https://web.stanford.edu/class/cs106l
Lecture 1¶
课程的第一课,不多说。
Lecture 2: Types and Structs¶
数据基本类型¶
和 C 语言类似,也就是 int、char、double 这类的。
有趣的是,C++ 可以使用 auto 关键字来让编译器自动指定变量的类型
namespace¶
参考链接:
https://zhuanlan.zhihu.com/p/126481010
https://www.runoob.com/cplusplus/cpp-namespaces.html
在 C++ 中,名称(name)可以是符号常量、变量、函数、结构、枚举、类和对象等等。工程越大,名称互相冲突性的可能性越大。另外使用多个厂商的类库时,也可能导致名称冲突。于是 C++ 就引入了 namespace 名称空间,我们这里就简单的介绍一下这个概念。
名称空间的定义就是:
定义好后,要使用这个名称空间的变量或函数,这样即可:
看下面这个例子吧:
#include <iostream>
using namespace std;
// 第一个命名空间
namespace first_space{
void func(){
cout << "Inside first_space" << endl;
}
}
// 第二个命名空间
namespace second_space{
void func(){
cout << "Inside second_space" << endl;
}
}
int main ()
{
// 调用第一个命名空间中的函数
first_space::func();
// 调用第二个命名空间中的函数
second_space::func();
return 0;
}
输出:
很好理解,对吧。
然后可以使用 using 命令来偷懒,using namespace name,使用命名空间 name时,就可以不用在前面加上命名空间的名称,编译器会帮忙搞定。
#include <iostream>
using namespace std;
// 第一个命名空间
namespace first_space{
void func(){
cout << "Inside first_space" << endl;
}
}
// 第二个命名空间
namespace second_space{
void func(){
cout << "Inside second_space" << endl;
}
}
using namespace first_space;
int main ()
{
// 调用第一个命名空间中的函数
func();
return 0;
}
最常用的名字空间就是 std 了,它是 STL 标准模版库的名字空间。C++ 的输入输出函数 cin 和 cout 就是 STL 库的。STL 库很强大,后面会多次用到。
下面输出一下 hello world 看看
相当于:
对于作用域解析运算符 ::, 最常用的还是在定义类方法的时候, 来指明该方法来自哪一个类.
overload¶
学习 Java 的时候已经使用过函数重载 overload 了,C++ 的也是类似的。函数可以重名,只要保证输入参数的类型或数量不同即可,例子如下:
#include <iostream>
using namespace std;
int half(int x) {
return x/2;
}
double half(double x, int divisor=2) {
// C++ 和 python 一样,支持默认参数!
return x/divisor;
}
int main() {
cout << half(3) << endl;
cout << half(3.0) << endl;
cout << half(3.0, 3) << endl;
return 0;
}
输出:
struct and pairs¶
C++ 中 struct 的使用和 C 相比更加方便了。例子如下:
struct Student {
std::string name;
std::string state;
int age;
}
Student s; //C 语言还要 typedef 一下
s.name = "Haven";
s.state = "AR";
s.age = 32;
// 初始化也可以写成:
Student s = {"Haven","AR",32};
STL 库中有一个 pair 模版,可以用来快速使用构造结构体。
<> 里的内容用来指定两个数据的类型,非常灵活。
此外,可以用 make_pair 函数快速生成 pair,连定义都省了。
Lecture 3: Initialization and References¶
Initialization¶
C++ 初始化的方式有两种。第一种是和 C 语言一样,使用等号。
你知道的,C++ 中的类型非常多,每种类型的初始化方式都不同,所以 C++11 又引入了新的初始化方式:Uniform initialization(统一初始化),它使用 {} 来初始化。
int a{12};
int b{12.5}; // Uniform initialization 非常关心变量类型,这里就会报错
std::map<std::string, int> ages{
{"Alice", 25},
{"Bob", 30},
{"Charlie",35}
}; // 对 map 初始化
std::vector<int> numbers{1,2,3,4,5}; // 对 vector 初始化
struct Student {
string name;
string state;
int age;
};
Student s{"Haven", "AR", 32}; // 对 struct 初始化
Student s = {"Haven","AR",32}; // 用 = 来初始化
Structured Binding¶
Structured Binding,中文名所谓的“结构化绑定”,是什么意思呢?这是 C++17 引入的特性。
先前我们的函数要返回多个参数的时候,应该怎么办呢?定义一个结构体即可:(例子来自https://zhuanlan.zhihu.com/p/139140185)
struct Person
{
std::string name;
int age;
};
Person CreatePerson()
{
return {"小岛秀夫赛高", 56};
};
int main()
{
auto person = CreatePerson();
std::cout << person.name << " " << person.age << '\n';
}
这个函数就可以返回人的姓名和年龄。但是有时候这个结构体只用一次,还专门去定义,就浪费了。那么我们看看下面的方式:
std::tuple<std::string, int> CreatePerson()
{
return { "小岛秀夫赛高", 56 };
}
int main()
{
auto[name, age] = CreatePerson();
// 和下面两种写法等价,但是下面要对 name、age 初始化,auto[name, age] 把初始化的工作也做了。
// std::tie(name, age) = CreatePerson();
// std::string &name = std::get<0>(person);
// int age = std::get<1>(person);
std::cout << name << " " << age << "\n";
}
利用 C++11 引入的新模版 tuple 来写这个函数,<> 里的内容是类型,auto[name, age] 就会自动根据括号里的类型来初始化变量。
Reference¶
reference 引用,是 C++ 中重要的概念之一。使用 & 运算符来进行。
可以把引用看成是指针的方便版本。
上面这个例子会输出 10。在 C 语言中,你可以这么实现:
如果在 C++ 中想要函数改变变量本身而不是传入形参,也就不用传入指针了,使用对应的引用类型即可:
引用值和原始值指向同一个地址,所以改变任何一个都可以。
下面看一个比较难的例子:
虽然上面这个函数的本意是希望将数组中的所有值都自增,但是有一个较难发觉的地方是,for 循环中的: 运算符本质上也是一个函数,它是返回一个新值,即为解包为单个元素的结果,而并非数组中的元素本身(我想起来和 Java 中的 Iterator 函数类似)。所以上面的函数不会产生任何结果,正确的做法是在 auto 后面增加 & 表示引用类型。
另外,实际上上面也用到了 structure binding 这个性质,还记得吗?
l-values and r-values¶
左值和右值。左值可以在赋值运算符 = 的左边或者右边,比如一个变量。而右值只能在 = 的右边,比如常量。
会想到 C 语言中一个经典的问题:如何快速避免在 if 表达式中将x==0 写成 x=0 这种问题? 答案很简单,就是写成 0==x 的形式,如果写成 0=x,编译器自然就会报错。这就是利用了右值不能被赋值的原理了。
然后就是在传参数的时候,右值是不可以传到引用类型的变量里去的,比如对于:
当然不能写成squareN(2) 的形式。还是比较好理解的。
常量¶
常量 const。
只有一点是新的,常量不能给非常量类型引用或者初始化,所以 int& b = a 会导致错误,而 const int &b = a 则语法正确。
Lecture 4: Streams¶
参考链接:https://www.runoob.com/cplusplus/cpp-basic-input-output.html
介绍¶
Streams 输入输出流这个概念是 C++ 中的重要概念。知道了它就可以使用高贵的 cin 和 cout,抛弃可怜的 scanf 和 printf 了。
那么到底什么是 stream 呢?stream 就是 C++ 为输入输出数据提供的一种抽象。抽象的作用就是提供高层的接口,避免直接和底层打交道。stream 的本质是字节序列,从 IO 设备读出或者写入 IO 设备。
在 C++ 中,使用 iostream 库来实现流,提供输入输出机制。iostream 中有两个基础类,istream 和 ostream,分别表示输入流和输出流。在标准库中,又定义了 4 个对象:cin,cout,cerr,clog。cin 是 istream 类型的实例,cout 和后面两个是 ostream 类型的实例。
输出流¶
还是来看一个例子吧:
上面的例子,很简单,就是打印 hello, world 到屏幕上。但是有一些细节需要说明。std::cout << "hello, world" << std::endl 本质上是一个表达式,<< 是一个输出运算符。(从现在开始要认识到 cout 不是一个函数了。)
<< 运算符接受两个运算对象,左侧的是一个 ostream 对象,右侧的运算对象是要打印的值。这个运算符将给定的值(右侧)写入到给定的 ostream 对象(左侧)中,就是说,计算结果就是写入给定值的左侧的 ostream 对象。
所以我们可以把表达式写成
或者是
得到的输出都是相同的。
那么这个 std::endl 又是怎么回事呢?endl 是一个被称为操纵符的特殊值,它的效果是结束当前行,并将缓冲区的内容全部刷新到设备中,清空缓冲区。
输入流¶
上面简单介绍了一下输出流,其实对于输入流也类似的。
>> 是输入运算符,接受 istream 类为左侧运算对象,将数据输入到右侧对象中,返回左侧对象作为运算结果。>> 读取 istream 的内容时,读到空格停止(和 scanf 一样)。
stream 提供了一种 universal 的方式来处理输入输出。
IO 类¶
除 istream 和 ostream 之外,标准库还定义了其他的一些 IO 类型,定义在三个独立的头文件中:iostream 定义了用于读写流的基本类型,fstream 定义了读写文件的类型,sstream 定义了读写字符串对象的类型。实际上,这三种 IO 类型是通过继承机制实现的,关系如下图所示:
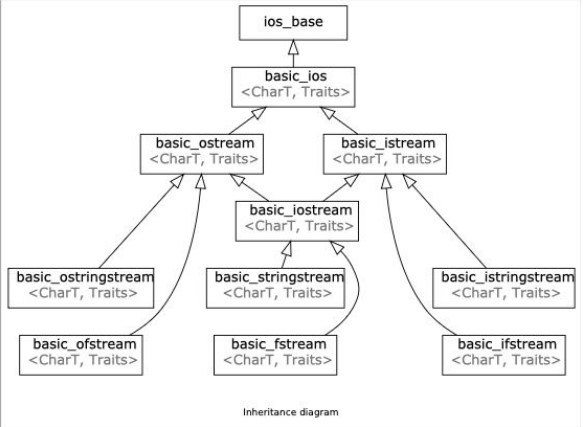
stringstream和 fstream 都是继承自 iostream 的。
先看一个 stringstream 的例子:
std::string initial_quote = "Bjarne Stroustrup C makes it easy to shoot yourself in the foot";
std::stringstream ss;
ss << initial_quote;
// stringstream 也可以像 cout 那样用输出运算符来赋值
std::string first;
std::string last;
std::string language, extracted_quote;
ss >> first >> last >> language;
// 可以用输入运算符对字符串赋值,就像 cin 那样,每一次赋值到空格结束
std::getline(ss, extracted_quote);
std::cout << first << " " << last <<" said this: " << language << " " << extracted_quote << std::endl;
如果直接用输入运算符,那么到空格就截止了。有时我们需要读入一整行,就像上面的 extracted_quote 那样,这时候就要使用 getline 函数。来看一下 getline 函数的原型:
getline() 函数读取一个输入流对象 is,直到遇到 delim 字符,并将读取结果储存在 str 中。默认的 delim 就是换行符 \n。注意:getline() 函数会消耗换行符。
然后我们再看一下文件流的例子。
int main() {
std::ofstream ofs("hello.txt");
if (ofs.is_open()) {
ofs << "Heloo CS106L!" << '\n';
}
ofs.close();
ofs << "this won't get written";
ofs.open("hello.txt");
ofs << "this will though! It’s open again";
return 0;
}
文件流的输入输出和 IO 也是类似的,就好像 fprintf 和 printf 之间的关系一样。
注意,fstream 对象在初始化时就已经打开了文件(如果文件存在),不要再 fs.open() 再打开一次,否则会导致 bug 出现。
int main() {
std::ofstream ofs("hello.txt");
//ofs.open("hello.txt"); 不要这样!
if (ofs.is_open()) {
ofs << "Heloo CS106L!" << '\n';
}
ofs.close();
return 0;
}
Heloo CS106L!
然后 ofstream 是输出文件流,直接从文件的最开始开始写入,覆盖文件已有的内容,而不是像 fwrite 那样先清空。
有时我们写入了乱七八糟的东西,要先清空的话,就要以特殊模式 out 来打开文件,即:
格式化输出¶
例子抄自这个链接:https://zhuanlan.zhihu.com/p/583649384
C++ 怎么用 cout 做到类似于 printf 的格式化输出呢?C++ 的 ostream 库中定义了大量的“流操纵算子”来控制输出。下面介绍一下:
整数不同进制输出¶
输出整数时用的流操纵算子有 dec,oct,hex 等等。在更改进制显示方式之后,系统默认后面使用该方式显示数据,如果有显示为其他进制形式的需要重新设置进制显示方式。
cout << "cout以不同进制显示整数***********************************************************" << endl;
/*cout以不同进制显示整数*/
i = 90;
cout << "以十进制显示i:" << dec << i << endl;//以十进制显示
cout << "以八进制显示i:" << oct << i << endl;//以八进制显示
cout << "以16进制显示i:" << hex << i << endl;//以16进制显示
//如需更改为十进制显示方式,则可以使用以下方式
cout.setf(ios_base::dec);
cout << "以十进制显示i:" << i << endl << endl;
/*bool数据类型显示*/
cout << "bool数据类型显示" << endl;
bool is_true = true;
cout.setf(ios_base::boolalpha);//可以显示为true或false
cout << "is_true = " << is_true << endl;
is_true = false;
cout << "is_true = " << is_true << endl << endl;
输出:
cout以不同进制显示整数***********************************************************
以十进制显示i:90
以八进制显示i:132
以16进制显示i:5a
以十进制显示i:90
bool数据类型显示
is_true = true
is_true = false
设置宽度¶
cout 使用 width 方法可以设置宽度。width() 只影响下一次的cout,然后字段宽度将恢复默认值。C++ 不会截断数据,如果显示字段宽度小于数字宽度,C++ 将增宽字段,以容纳该数据,如最后一个例子。
cout << "width()***************************************************************************" << endl;
int w = cout.width(30);
cout << "default field width = " << w << ":\n";
cout.width(5);
cout << "N" << ':';
cout.width(8);
cout << "N * N" << ":\n";
for (long i = 1; i <= 100; i *= 10)
{
cout.width(5);
cout << i << ':';
cout.width(8);
cout << i * i << ":\n";
}
cout.width(5);
cout << 9.888889999 << endl;//将不会截断
运行结果
width()***************************************************************************
default field width = 0:
N: N * N:
1: 1:
10: 100:
100: 10000:
9.88889
更改填充字符¶
fill() 方法更改空位填充的字符(默认是空格),也是全局设定,更改后系统都用这个字符填充。
cout << "更改填充字符****************************************************************************" << endl;
cout.fill('*');
const char* staff[2] = { "Waldo Whipsnade", "Wilmarie Wooper" };
long bonus[2] = { 900, 1350 };
for (int i = 0; i < 2; i++)
{
cout << staff[i] << ": $";
cout.width(7);
cout << bonus[i] << "\n";
}
输出:
更改填充字符****************************************************************************
Waldo Whipsnade: $****900
Wilmarie Wooper: $***1350
更改显示精度¶
precision 方法可以更改显示精度,也是全局设置。
cout << "设置小数显示精度:precision()***********************************************************" << endl;
double j = 3333.1415926;
/*设置显示有效数字位数*/
cout << "默认情况显示(6位):" << j << endl;//输出浮点数时,默认情况下保留六位有效数字
cout.precision(9);//可以使用cout.precision(n)设置输出浮点数时保留n位有效数字
cout << "设置有效数字位数为9位时:" << j << endl;
cout.precision(3);//当有效数字位数小于整数有效数字位数时,使用科学计数法显示
cout << "设置有效数字位数为3位时:" << j << endl << endl;
输出
设置小数显示精度:precision()***********************************************************
默认情况显示(6位):3333.14
设置有效数字位数为9位时:3333.14159
设置有效数字位数为3位时:3.33e+03
总的来说感觉还是 printf() 好用?但是人要学会接受新事物。
Lecture 5: Containers¶
Container 容器,就是对象的集合。更准确的说,container is an object that allows us to collect other objects together and interact with them in some way.
我们用过的 vectors,stacks,queues 都是所谓的 container 类型。已经比较熟悉了,下面就只简单介绍 vector。
vector<string> v{"hello", "hi", "qq"}; //初始化
v.push_pack("va"); //"va"添加到vector的最后
v.empty(); //v 是否为空
v.size(); //元素个数
v[n]; //第n个位置上的元素引用
v1 = v2; // v2 中的元素拷贝替换v1中的元素
v1 = {a,b,c ...} //列表中的元素拷贝替换v1中的元素
v1 == v2; //元素数量和元素值是否相同
v1 != v2;
v1 < v2; //字典顺序比较
Lecture 6: Iterators and Pointers¶
要访问容器中的对象,除了用下标运算符,也可以使用 iterator(迭代器)实现。而且,大部分标准库容器都支持迭代器(除了 stack 和 queue 以外),但是只有少数几种还同时支持下标运算符。
对一个容器对象,我们可以用 begin 和 end 获得迭代器。begin 指向第一个元素,end 指向最后一个元素的下一个位置。
迭代器支持的运算如下:
*iter; //返回迭代器所指元素的引用
iter->mem; //相当于(*iter).mem
++iter; //让迭代器指示容器的下一个元素
--iter; //让迭代器指示容器的上一个元素
iter + n; // 向后/向前移动 n 个元素
iter1==iter2;
iter1!=iter2;
//判断两个迭代器是否相等:是否指示同一个元素或者是同一个容器的尾后迭代器
iter1-iter2; //比较两个迭代器的距离
iter1<iter2; //判断先后位置
如何获得 container 里面的元素?下面提供一个示例:
std::map<int,int>{{1,6},{2,8},{0,3},{3,9}};
for(auto iter = map.begin();iter != map.end();iter++) {
const auto& [key, value] = *iter;
}
上面我们可以看到,迭代器的用法很像指针。那么它和指针有什么联系和区别吗?
https://www.geeksforgeeks.org/difference-between-iterators-and-pointers-in-c-c-with-examples/
首先要知道,迭代器并不是指针,它的类型是这样的:
std::vector<int>::iterator it1;
std::string::iterator it2;
std::vector<int>::const_iterator it3;
std::string::const_iterator it4;
可以看到,迭代器是一个对象,它可以包含比地址更多的东西,而指针只包含地址。
指针通过自增、自减可以遍历连续地址空间的元素;然而有一些容器,它的元素的地址不是连续的,迭代器的自增和自减仍然可以遍历,这就说明了迭代器包含的不仅仅是地址。
可以这样理解,迭代器是指针的高级抽象。
Lecture 7: Class¶
来到最重要的部分了。(话说你的形容词除了重要能不能换点别的)(rewarding 咋样)
我们已经在 python 和 Java 中都使用过 Class 了。C++ 中的写法和特性又有所不同(思想还是一样的)。
类的声明放在同名的头文件(.h 文件)中,类的定义放在同名的 .cpp 文件中。
下面是类的声明:
// Student.h
class Student {
private:
std::string name;
std::string state;
int age;
public:
Student();
Student(std::string name, std::string state, int age);
~Student();
std::string getName();
std::string getState();
int getAge();
void setName(std::string name);
void setState(std::string state);
void setAge(int state);
};
然后是类的定义(实现):
// Student.cpp
#include "Student.h"
// constructor
// 需要名字空间,名字空间和类名相同
Student::Student(std::string name, std::string state, int age) {
this->name = name;
this->state = state;
this->age = age;
}
// 函数重载
Student::Student() {
name = "John";
state = "Appleseed";
age = 18;
}
// Destructor
Student::~Student(){};
std::string Student::getName() {
return this->name;
}
std::string Student::getState() {
return this->state;
}
int Student::getAge() {
return this->age;
}
void Student::setName(std::string name) { this->name = name; }
void Student::setState(std::string state) { this->state = state; }
void Student::setAge(int age) {
if ( age >= 0) {
this->age = age;
}
}
上面就是一个完整的 Student 类实现了。我们可以在代码中使用这个类。注意, 有多种方式使用构造函数来初始化一个新的类.
Student s = Student("Haven", "AR", 21); // 最基本的, 显式调用构造函数
auto s1 = Student(); // 可以用 auto, 让编译器来决定
Student s2{"Peter","kka",22}; // uniform initialization, 好用爱用
Student s3("Ama", "lo", 12); // 隐式调用构造函数
Student* p = new Student("Prata", "TE", 67); // 用 new, 返回一个指针来管理类
cout << s.getAge()<< a << endl;
s1.setName("Jack");
cout << s.getName() << s1.getName() << s2.getName() << s3.getName() << p->getName() << endl;
然后再来看一下 C++ 是怎么实现继承的,也很简单:
class Shape {
public:
virtual double area() const = 0;
};
class Circle : public Shape {
private:
double _radius;
Circle(double radius): _radius{radius} {};
double area() const {
return 3.14 * _radius * _radius;
}
};
值得一提的是,在 C++ 中,类的本质是 struct。(TODO 阅读 C++ primer)
Lecture 8: Template Classes and Const Correctness¶
Template Class¶
模版有什么作用? 之前在学数据结构课的时候, 写了一个 stack. 然后那个 stack 只能存储 int 类型的. 结果麻烦来了, 过了几天, 要存储 double 类型了, 再过几天, 要存储字符串了. 那该怎么办呢? 只能复制一份, 然后把里面的类型都改掉吗? 模板就是为了解决这个问题而诞生的.
先看上面的代码, 这个类是不是就碰到了上面的问题呢, 只能储存 int 类型的变量. 然后我们看看下面的类模板是怎么解决这个问题.
// Container.hh
template <typename T>
class Container {
public:
Container (T val);
T getValue();
private:
T value;
};
然后再来看一下 cpp 怎么实现
//Container.cpp
#include "Container.hh"
template <class T>
Container<T>::Container(T val) {
this->value = val;
}
template <typename T>
T Container<T>::getValue() {
return value;
}
在模版声明时, typename 和 class 两个关键字可以互换.
你直接拿去运行, 结果发现报错了, 怎么回事? 这就是 C++ 神金的地方了. 下面的链接给出了一些答案.
https://blog.csdn.net/amnesiagreen/article/details/108575310
http://www.uml.org.cn/c++/20112284.asp
通常情况下, 我们会把类的定义和方法的声明放在 .h 文件中, 把方法的定义放在 .cpp 文件中. 但是对于上面的类模板, 这样做就不行了. 因为当实例化一个模板时,编译器必须看到模板确切的定义,而不仅仅是它的声明。 因此,最好的办法就是将模板的声明和定义都放置在同一个.h文件中。 另外, STL 库好像就是这么干的. (有毒)
另外, 经过测试, 编译器对于模版是会进行特殊处理的, 将定义和声明放在一起并不会导致重定义的编译错误.
链接中还提到了 export 关键字的方法, 这个已经过时了, 就不要使用了.
Const Correctness¶
const 其实有很多的细节要注意的. 下面就讲解除了修饰常量类型以外, 另外的用法.
介绍¶
// Student.h
class Student {
private:
std::string name;
std::string state;
int age;
public:
Student();
Student(std::string name, std::string state, int age);
~Student();
std::string getName();
std::string getState();
int getAge();
void setName(std::string name);
void setState(std::string state);
void setAge(int state);
};
我们添加一个函数
std::string stringify(const Student& s) {
return s.getName() + " is " + std::to_string(s.getAge()) + " years old.";
}
const. 如果一个参数前面声明了 const, 就表示它是常量, 那么就要保证, 在运行的整个过程, 这个参数都不能改变. 但是目前, 编译器不能确定 s.getName() 和 s.getAge() 会否改变 s.
那么该怎么办呢? 我们要做的就是在方法里也声明 const, 来保证我们不会改变这个参数, 如下所示:
// Student.h
class Student {
private:
std::string name;
std::string state;
int age;
public:
Student();
Student(std::string name, std::string state, int age);
~Student();
std::string getName() const;
std::string getState() const;
int getAge() const;
void setName(std::string name);
void setState(std::string state);
void setAge(int state);
};
然后在方法的定义里面也记得改:
std::string Student::getName() const {
return this->name;
}
std::string Student::getState() const {
return this->state;
}
int Student::getAge() const {
return this->age;
}
简而言之, 就是 Objects that are const can only interact with the const-interface, which is the functions don't modify the object of the class. 被 const 修饰的对象, 只能被 const 接口调用
const 修饰类成员函数,其目的是防止成员函数修改被调用对象的值,如果我们不想修改一个调用对象的值,所有的成员函数都应当声明为 const 成员函数。
一个例子¶
然后我们来看一个神金的例子: const T& data() const { return data_; } (例子来自https://stackoverflow.com/questions/16449889/why-using-the-const-keyword-before-and-after-method-or-function-name)
主要是要搞清楚两个 const 的区别.
第一个 const 就是和之前一样, 表示返回的是常量类型. 这里是 T 的引用. 常量只能给常量类型初始化, 否则会导致错误. 如下例子所示:
第二个 const 是今天所学, 是一种声明, 声明这个类方法函数绝对不会改变类中的内容, 是一个 const interface. 如下例子所示:
void Class::get_data() const {
this->data_ = ...; // is not allowed here since get_data() is const (unless 'data_' is mutable)
this->anything = ... // Not allowed unless the thing is 'mutable'
}
mutable 是什么关键字, 下次再说吧...)
const casting¶
偶尔也许在被 const 类型修饰的类方法函数里, 要调用那些没有 const 保证的函数, 此时该怎么做呢? 当然是用 C 中臭名昭著的 casting (类型转换) 了. 见下面例子:
int& findItem(int value) {
for (auto& elem: arr) {
if (elem == value)
return elem;
}
throw std::out_of_range("not found");
}
const int& findItem(int value) const {
return const_cast<IntArray>(*this).findItem(value);
}
到这里, 应该感受到 C++ 的复杂性了.
Lecture 9: Template Function¶
上一章讲了类模板, 这一章看一下函数模板.
模版函数的写法类似:
调用这个函数需要指定 Type:
当然也有偷懒的办法, 叫 template argument deduction, 让编译器来推断类型
template <typename T, typename U>
auto smarterMyMin(T a, U b) {
return a < b ? a : b;
}
cout << smarterMyMin(3.2, 4) << endl;
编译器为我们确定模版类型的过程称为模板的实例化. 直到实例化时, 才会生成代码
值得一提的是, All algorithms are fully generic, templated functions in the STL algorithm library!
Lecture 10: Functions and Lambdas¶
这一节课的主要内容就是, 函数作为函数的参数, 可不可以? 都学到这份上了, 就别装了, 当然是可以的, 用函数指针就可以轻松完成. 回调函数不就是一个典型的函数参数吗.
OK, 看下面的例子, 函数指针作为模版函数的参数:
template<typename InputIt, typename Unipred>
int count_occurences(InputIt begin, InputIt end, Unipred pred) {
int count = 0;
for (auto iter = begin; iter != end; ++iter) {
if (pred(*iter)) {
count++;
}
}
return count;
}
bool isVowel(char c)
{
std::string vowels = "aeiou";
return vowels.find(c) != std::string::npos;
}
int main()
{
std::string str = "Peter";
std::cout << "number of vowel is: " << count_occurences(str.begin(), str.end(), isVowel) << "\n";
}
但是, 我们仍然还不太满意. 如果预测函数 pred 是要和某一个值比大小呢? 要 isMorethan3, isMorethan4, isMorethan5... 这样子吗? 一种方法是修改函数为二参数函数就行, 但是有时写代码还有一种方法就是为了引出主角, lambda.
Lambdas are inline, anonymous functions that can know about variables declared in their same scope.
Lambda 函数的形式如下:
[] 中提供外部参数, param 就是函数参数, {} 中是函数主体, var 指向 lambda 函数的首地址. -> 后是指定的返回类型, 若 lambda 表达式包含除 return 之外的语句则必须指定, 否则默认返回 void 类型.
举个例子,
int limit = 5;
auto isMoreThan = [limit] (int n) { return n > limit; };
// isMoreThan(4) is true
std::vector<int> nums = {3, 5, 6, 7, 9, 13};
count_occurences(nums.begin(), nums.end(), isMoreThan);
Lecture 11: Operators Overloading¶
这节课介绍一下 C++ 中的运算符重载.
1. 运算符重载¶
一般来说, 运算符用于基本数据类型. 但是我们也可以通过重载, 将运算符作用于类类型的运算对象.
C++ 中大部分的运算符都可以重载, 作为笔记, 就不详细介绍反例了.
类本身是不支持某些运算符的, 但是我们只要添加一个运算符的成员函数, 就可以使它支持了.
举例, 看下面的 Time 类.
//mytime2.hh
#ifndef MYTIME2
#define MYTIME2
class Time
{
private:
int hours;
int minutes;
public:
Time();
Time(int h, int m = 0);
Time operator+(const Time &t) const;
Time operator-(const Time &t) const;
Time operator*(double mult) const;
void Reset(int h=0, int m=0);
void Show() const;
};
#endif
//mytime2.cpp
#include <iostream>
#include "mytime2.hh"
Time::Time()
{
hours = minutes = 0;
}
Time::Time(int h, int m)
{
hours = h;
minutes = m;
}
Time Time::operator+(const Time &t) const
{
Time sum;
sum.minutes = minutes + t.minutes;
sum.hours = hours + t.hours + sum.minutes / 60;
sum.minutes %= 60;
return sum;
}
Time Time::operator-(const Time &t) const
{
// Omit
Time diff = Time();
return diff;
}
Time Time::operator*(double mult) const
{
//Omit
return Time();
}
void Time::Show() const
{
std::cout << hours << " hours, " << minutes << " minutes" << std::endl;
}
//main.cpp
#include <iostream>
#include "mytime2.hh"
int main(int, char**){
Time atime(4 ,35);
Time btime(2, 47);
Time total, diff, adjust;
total = atime + btime;
diff = atime - btime;
adjust = atime * 1.5;
total.Show();
diff.Show();
adjust.Show();
return 0;
}
上面我们将 +, - , * 三个操作符, 作为类的成员函数(member function), 进行了重载, 从而实现了时间的加减乘方法.
值得一提的是, 这里操作符最终的行为就是函数的调用, 比如, atime * 1.5 相当于 atime.operator*(1.5). 所以想一想就知道, 不能写成 1.5 * atime 的形式, 因为左侧的操作数应该是调用对象, 而 1.5 不是一个对象. 所以, 上面的方法还有局限性, 下面将介绍利用友元, 进行非成员函数的运算符重载.
2. 友元¶
非成员函数的运算符重载需要用到友元的概念. 一个友元函数在类声明中用关键字 friend 声明, 表示它不是一个成员函数, 但是和成员函数有相同的访问权限.
仍然以上面的例子为例:
创建乘法的友元函数声明:
创建函数定义. 注意, 由于不是成员函数, 所以不要使用 Time:: 限定符. 另外, 不要在定义中使用关键字 friend, 如下所示:
Time operator*(double m, const Time& t)
{
Time result;
long tm = t.hours * m * 60 + t.minutes * m;
result.hours = tm / 60;
result.minutes = tm % 60;
return result;
}
注意看上面的定义, 如果 oprator* 不是一个友元函数, 那么它不能访问 hours 和 minutes 成员, 因为它们都是 private 类型的. 但是我们在声明中用 friend 声明了它是类的友元, 于是就有了和类成员相同的访问权限.
这样, 1.5 * atime 就等价于 operator*(1.5, atime).
然后再看一个例子, 重载输出运算符, 由于 ostream 类必定在左边, 所以肯定也是要用非成员函数的. 重载输出运算符, 我们就可以直接按我们想要的方式用 cout 输出类了.
// declaration
friend std::ostream& operator<< (std::ostream & out, const Time& time);
// definition
std::ostream& operator<< (std::ostream & out, const Time& time)
{
return out << "operator overload time: " << time.hours << ":" << time.minutes << "\n";
}
Lecture 12: Special Member Function¶
C++ 的类有一些特殊成员函数, 就算我们不直接定义, 编译器也会帮我们直接合成. 这样的成员函数包括:
- default constructor 默认构造函数
- copy constructor 拷贝构造函数
- copy assignment operator 拷贝复制运算符
- destructor 析构函数
- move constructor 移动构造函数
- move assignment operator 移动赋值运算符
它们对应的形式如下:
class Widget {
public:
Widget();
Widget(const Widget& w);
Widget& operator=(const Widget& w);
~Widget();
Widget(Widget&& rhs);
Widget& operator=(Widget&& rhs);
}
默认构造函数没什么好说的. 只有在你没定义构造函数的时候, 编译器才会合成默认构造函数, 否则是不会合成的. 可以用 default 和 delete 关键字来显式的说明要不要使用合成的默认构造函数. 对其他的特殊成员函数也适用. (注意, 析构函数不能用 delete, 不然无法释放空间)
对于拷贝, 赋值和析构, 我们还是看看下面的例子, 简单理解一下吧.
using std::vector;
vector<int> fun(vector<int> vec0) {
vector<int> vec1;
vector<int> vec2(3);
vector<int> vec3{3};
vector<int> vec4();
vector<int> vec5(vec2);
vector<int> vec{vec3 + vec4};
vector<int> vec8 = vec4;
vec8 = vec2;
return vec8;
}
return vec8 也是调用了拷贝构造函数, 将 vec8 的值写到对应的内存中. 最后函数结束, 所有局部变量对象都使用析构函数销毁.
TODO: 考虑一下, 返回结构体不能保存在寄存器中, 是怎么返回的呢? 我感觉大概是直接保存到上一个函数栈的某一个位置.
有的时候, 我们不满足于默认的拷贝函数而要自己重载一个, 这是可以的. 想想有哪些情况呢?
对于特殊成员函数的重载, 有规则0: "If the default operations work, then don't define your own." 和规则3: "If you explicitly define a copy constructor, copy assignment operator, or destructor, you should define all three."
Lecture 13: Move Semantics¶
下面进一步介绍特殊成员函数中的移动构造函数和移动赋值运算符,即 move 类型的。
stackoverflow 中有很好的例子:https://stackoverflow.com/questions/3106110/what-is-move-semantics?newreg=7ef8506e56544c8492d025934de2b2d0
要介绍移动,首先从左值和右值开始。左值可以放在赋值语句的左边或右边,右值只能放在赋值语句的右边。更深层次的考虑是:左值的对象存储在内存区域中,持久存在;右值的变量是一个具体的数值,是临时的。
继续介绍一下引用。
之前 C++ 中提到的引用,std::string& ref; 是左值引用,必须指向一个左值。
而 && 是右值引用,可以指向一个右值,std::string&& rrstr;。
这样的引用,帮助我们实现移动语义。来看看 C++ 的移动函数,std::move()。
它将传入的对象转换为一个右值引用,这使得传入的对象成为了一个临时变量,在赋值结束后就被销毁,从而实现了移动。
举个例子:
int main() {
vector<string> vec1 = {"hello", "world"}
vector<string> vec2 = std::move(vec1);
vec1.push_back("Sure hope vec2 doesn’t see this!") // error
}
在 move() 被调用后,vec1 成为临时变量,赋值后随即释放,故第三句代码就会报错。
Lecture 14: std::optional, Type Safety¶
1. std::optional¶
std::optional 是 C++17 中引入的一个特性。
Lecture 15: Smart Pointers¶
这一章我们来看一下智能指针。C++ 中的智能指针是怎么回事呢?C 语言中如果忘记释放内存,就可能造成内存泄露。于是 C++ 就提供了智能指针,来自动释放管理的对象。智能指针包括三种指针:
shared_ptr:允许多个指针指向同一个对象unique_ptr:独占所指向的对象weak_ptr:一种弱引用,指向shared_ptr管理的对象
这三种指针定义在 memory 头文件中。下面主要以 shared_ptr 为例子讲解。
1. shared_ptr¶
和 vector 一样,智能指针也是模板类。因此创建智能指针时,必须提供指针指向的类型。例如:
智能指针的使用方式和普通指针类似,解引用返回其指向的对象。
我们使用 make_shared 函数来初始化智能指针,分配内存。make_shared 是一个模板函数,函数名后跟一个尖括号给出参数类型。
shared_ptr<int> p3 = make_shared<int>(42);
shared_ptr<string> p4 = make_shared<string>(10, '9');
auto p6 = make_shared<vector<string>>();
智能指针通过计数器来管理何时释放内存。每当进行拷贝和赋值操作时,shared_ptr 都会记录有多少个其他 shared_ptr 指向相同的对象,这个计数称为引用计数。当我们拷贝(如初始化、参数传递、函数返回)一个 shared_ptr 时,其计数递增,反之我们给其赋值或者销毁(如离开作用域),那么计数器就会递减。当一个 shared_ptr 的计数器变为 0 的时候,它就会自动释放自己管理的对象。
p 和 q 指向相同对象,此对象有两个引用者。
现在 q 指向的对象的引用计数再加 1,而 r 原先指向的对象没有引用者,于是自动释放。
用智能指针有什么好处呢?我们可以看下面的例子进行对比。
不使用智能指针,用传统方式分配内存:
使用智能指针:
看似两者差不多,但是如果考虑多线程的情况就不一样了。可能有一个线程在调用的时候触发了异常退出了,如果是前面传统的方式,就无法执行 delete n,而导致内存泄露。而智能指针,在变量离开作用域时就会自动释放内存,从而解决了这个问题。
智能指针利用了 RALL(Resource Acquisition is Initialization)的思想。具体来说有两点:在初始化后获得资源,离开作用域时立刻释放资源,避免中间态的产生。操作系统中的锁设计也用到这个思想。(原子化思想)
如果有一个线程突然退出,按前者的方式将导致锁永远无法关闭,导致其他线程无法进入临界区。而后者解决了这一问题。
下面是 copilot 给出的一段智能指针的例程,不得不感慨大模型的强大了,写的代码也是非常的易懂好用!甚至连 move 都搞清楚了。
#include <iostream>
#include <memory>
class MyClass {
public:
MyClass() {
std::cout << "MyClass Constructor" << std::endl;
}
~MyClass() {
std::cout << "MyClass Destructor" << std::endl;
}
void display() {
std::cout << "Hello from MyClass" << std::endl;
}
};
void uniquePtrExample() {
std::unique_ptr<MyClass> ptr1 = std::make_unique<MyClass>();
ptr1->display();
// std::unique_ptr不能被复制,但可以被移动
std::unique_ptr<MyClass> ptr2 = std::move(ptr1);
if (!ptr1) {
std::cout << "ptr1 is now nullptr" << std::endl;
}
ptr2->display();
}
void sharedPtrExample() {
std::shared_ptr<MyClass> ptr1 = std::make_shared<MyClass>();
{
std::shared_ptr<MyClass> ptr2 = ptr1;
std::cout << "ptr1 use count: " << ptr1.use_count() << std::endl;
std::cout << "ptr2 use count: " << ptr2.use_count() << std::endl;
ptr2->display();
}
std::cout << "ptr1 use count after ptr2 goes out of scope: " << ptr1.use_count() << std::endl;
ptr1->display();
}
int main() {
std::cout << "Unique Pointer Example:" << std::endl;
uniquePtrExample();
std::cout << "\nShared Pointer Example:" << std::endl;
sharedPtrExample();
return 0;
}