实验手册¶
本文是Peter的NJU PA的实验手册。只记录一些东西,不提供源代码。
课程网址在这里。
PA0 (tools)¶
If you have problems in conflicting debs, just use the original source rather than tsinghua or ustc. It wastes a lot of time.
包冲突的解决:直接用ubuntu提供的源即可,不用阿里云或者清华云了。可以保证下载速度的,也不会有冲突。
终于可以输入中文了。好骚的sogou输入法.
先安装一些必要的工具:
apt-get install build-essential # build-essential packages, include binary utilities, gcc, make, and so on
apt-get install man # on-line reference manual
apt-get install gcc-doc # on-line reference manual for gcc
apt-get install gdb # GNU debugger
apt-get install git # revision control system
apt-get install libreadline-dev # a library used later
apt-get install libsdl2-dev # a library used later
apt-get install llvm llvm-dev # llvm project, which contains libraries used later
apt-get install vim # vim
apt-get install vim-gtk # vim-more
C语言¶
沧海遗珠的细节
macro¶
一是讨论一下#include的路径.
若是用<>那么就是在标准目录中寻找文件
若是用"", 就是在当前目录(c文件所在的位置)寻找文件. 写法和linux中目录的写法一致, 比如在上级文件夹下的另一个文件夹, 可以写成#include "../another/hello.h"
一般要把函数声明放在头文件中, 这样可以需要这个函数的c文件引用这个头文件就可以使用该函数了.
头文件的内容一般包含: 明显常量, 宏, 函数声明, 结构模板定义和类型定义.
在去年上数据结构课的时候, 碰到过这样的问题, 有多个文件引用list.h, 导致list.h中的结构类型node被重定义的问题.
c语言中,声明可以重复很多次, 但是定义只能有一次
怎么解决这个问题呢, 就是用条件编译指令了:
#ifndef LIST
#define LIST
struct Node;
typedef struct Node *PtrToNode;
typedef PtrToNode List;
typedef PtrToNode Position;
List MakeEmpty(List L);
int IsListEmpty(List L);
int IsLast(Position P,List L);
void Insert(char X[], List L);
Position Find(char X[],List L);
struct Node{
char* Element;
Position Next;
};
#endif
如上所示ifndef指令保证结构类型只被定义一次. ifndef指令常常用于防止多次包含同一文件, 保证这个文件只被包含一次.
作用域和链接¶
作用域¶
一个C变量的作用域可以是代码块作用域/函数原型作用域/文件作用域.
对于一个全局变量来说, 它具有文件作用域, 整个文件都可以使用它
链接¶
c变量可以有外部链接/内部链接/空链接
对于一个局部变量来说, 它是只有空链接, 由代码块或者函数原型私有, 只有文件作用域的变量才讨论内部还是外部链接.
giant就具有外部链接, 其他文件都可以使用giant, 只要加上extern关键字:
但是dog有static标识, 那么他就是main.c所私有的, 其他文件无法访问. 这里static声明是说该全局变量具有内部链接.
Tips
注意:
是声明 是定义。 C语言声明可以有很多次,而定义只能有一次。故若要使用同名的独立的全局变量,必须加 static 关键字。而如果使用的是外部变量,除非是第一次定义,否则必须加 extern 声明。如果在两个文件中同时定义了int giant,则会报错。
存储时期¶
static还有一个地方会碰到, 就是声明一个变量是静态存储时期. 一般的变量都是自动存储时期, 作用域结束就释放. 而静态存储时期的变量, 在整个程序执行期间一直存在. 很显然, 不管加不加static, 全局变量都一定是静态变量. 自动变量不初始化, 静态变量缺省地初始化为0.
字符串处理函数:¶
strtok
用于字符串切割
char *strtok(char *str, const char *delim)
- str -- 要被分解成一组小字符串的字符串。
- delim -- 包含分隔符的 C 字符串。
该函数返回被分解的第一个子字符串,如果没有可检索的字符串,则返回一个空指针。
#include <stdio.h>
#include <string.h>
int main() {
char str[90] = "I love you So much";
char* token;
token = strtok(str, " ");
char* a;
a = strtok(NULL, " ");
char* b;
b = strtok(str+strlen(token)+1, " ");
printf("%s\n", token);
printf("%s\n",a);
printf("%s\n",b);
return 0;
}
会输出如下结果
注意:
-
strtok是会改变原字符串的, 在str的第一个被分隔的位置将delim中对应的字符替换成\0 -
如果要继续分割当前字符串,
a = strtok(NULL, " ");即可, 和b = strtok(str+strlen(token)+1, " ");的效果是一样的,strlen(token)是前面被分割的总长度. -
没有了, 就这样.
strncpy
char *strncpy(char *dest, char *src, size_t n)
将src赋值到dest, 返回dest的首地址, 最多复制n个字符
sprintf
int sprintf(char* dest, char *format_string, ...)
将格式化字符串输出到dest中
sscanf
int sscanf(const char *src, const char *format, ...)
和scanf基本一样, 只是sscanf是从src中读取数据.
inline 和 volatile 关键字¶
内联函数的参考链接: https://blog.csdn.net/zqixiao_09/article/details/50877383
如果一个函数定义用 inline 关键字修饰的话, 表示它是内联函数, 它的编译结果将不使用栈空间, 而是就如同普通的代码一样运行. 所以内联函数是没有函数地址的.
标准规定具有内联函数的定义与调用该函数的代码必须在同一个文件中, 所以定义内联函数通常都同时使用关键字 static 和 inline.
举个例子:
只有在运行简单的函数时, 内联函数才有优化效果. 如果函数复杂, 每一处调用函数的部分都要复制一份这样的代码, 这样很占用内存(原本跳转到函数地址, 只需要一份代码即可). 而且, 复杂的代码, 用内联节省不了多少时间. 另外, 内联函数是不能执行递归的, 因为普通函数的递归是栈实现的.
volatile 关键字则表示某个变量是可变的, 要求编译器每次使用这个变量时都要从内存中重新读取. 注意, 有时做了优化, 想速度快一点, 编译器编译出的代码会直接从寄存器读取, 但是如果有多个线程的情况下, 另外一个线程可能会改变变量的值, 导致内存中的值和寄存器中的值不符. 对于这种情况, 我们就要用 volatile 来声明变量.
如下面的例子
如果没有 volatile, 编译器在执行b = i 时可能就直接优化成 b = a, 但是可能另外一个线程会改变 i, 这样就会导致变量 b 被赋错误的值.
内联汇编¶
参考链接:https://www.ibiblio.org/gferg/ldp/GCC-Inline-Assembly-HOWTO.html#toc2
https://blog.csdn.net/lyndon_li/article/details/118471845
语法很简单:
两种都可以。如果有多条指令,每行都加双引号,每行的结尾都加换行符和 tab 键。
asm ("movl %eax, %ebx\n\t"
"movl $56, %esi\n\t"
"movl %ecx, $label(%edx,%ebx,$4)\n\t"
"movb %ah, (%ebx)");
前面都是很直接的嵌入汇编指令,还有扩展内联汇编,可以指定操作数,和 c 语言的变量进行交互。扩展内联汇编的语法如下:
asm ( assembler template
: output operands /* optional */
: input operands /* optional */
: list of clobbered registers /* optional */
);
: 号。
举个例子吧:
#include <stdio.h>
int main()
{
int a = 10;
int b = 20;
int c;
int d;
asm("movl %3, %%eax \n"
"movl %%eax, %1 \n"
:"=b"(c),"=c"(d)
:"d"(a),"S"(b)
:"%eax"
);
printf("d = %d\n", d);
}
解释一下,一个 % 表示操作数,两个 % 表示寄存器。数字表示操作数的顺序,从 0 开始。第二、第三部分中的操作数前的引号内的内容是修饰符,常见的修饰符,= 表示只写操作数只写(输出操作数),a/b/c/d/S/D 表示将操作数放入 eax/ebx/ecx/edx/esi/edi,r 表示将输入变量放入上述任一通用寄存器。
于是上面的汇编代码,%3 表示汇编代码中第 4 个操作数,即 b, %1 表示第 2 个寄存器,即 d,很容易知道,最后 d 的值是 20,故上述代码输出 20。
为了防止汇编代码被编译器优化,可以加上 volatile 关键字
clash¶
首先照readme将url改成订阅地址
后面 按提示即可
sudo bash start.sh
source /etc/profile.d/clash.sh
proxy_on 打开代理
proxy_off关闭代理
sudo bash shutdown.sh关闭程序
这样弄好以后,再打开系统的代理:
ubuntu桌面版,右上角点击设置,网络,网络代理,手动,然后把http://127.0.0.1和7890
Then you can google and github freely.
gcc¶
-g 增加调试指令
gcc 可以增加警告,警告视作错误。
gcc 可以只输出宏定义展开,不编译。
gdb¶
Starting:¶
Running and Stopping:¶
quit ---- exit gdb
**please run the program before debug...**
run ---- run the program(<file>)
run 1 2 3 ---- run program with command-line arguments 1 2 3
kill ---- stop the program
Breakpoint:¶
info break ---- list all breaks
(b)
break <func> ---- Set breakpoint at the entry to <func>
break *0x80483c3 ----Set breakpoint at address 0x80483c3
break 9 ---- Set breakpoint at line 9
break main.c:9 if q==0 ---- conditional breakpoint
delete ---- delete all breakpoints
delete 1 ---- delete the breakpoint 1
disable 1 ---- disable the breakpoint 1
enable 1 ---- enable the breakpoint 1
clear <func> ---- Clear any points at the entry to <func>
(w)
watch *地址 # 当地址所指内容发送变化时断点
watch var #当var值变化时,断点
watch (condition) #当条件符合时,断点
Execution:¶
stepi ---- Execute 1 instruction (assemble instruction)
stepi 4 ---Execute 4 instruction (assemble instruction)
nexti ---- Execute 1 instruction, but it doesn't enter the function and just execute it
step ---- Execute one C statement
next ---- Execute one C Statement but doesn't enter the function.
c(continue) -- -- execute to the next breakpoint
until 3 ---- continue exec until the breakpoint 3
finish ---- Resume execution until the current function return.
call <func> ---- call the func and print the return Value
Examining code:¶
(p)
print /d $rax ---- Print contents of %rax in decimal
print /x $rax ---- Print contents of %rax in hex
print /t $rax ---- Print contents of %rax in binary
print /d (int)$rax ---- Print contents of %rax in decimal but it has signs.
Examine:
x/[num][size][format] address
num = number of objects todisplay
size = size of each project (b=byte h=half-word, w=word, g=quad-word)
(1 word = 4 Byte)
FORMAT = how to display each object (d=decimal, x=hex, o=octal, etc.)
for example:
x/w $rax
x/2wd 0xbffff890
x/200bc $rdi
x/s $rsp (a string)
x/6i 0x200 打印地址 0x200 开始的 6 条指令
注意,p 用来打印寄存器的值,x 用来打印地址储存的值
Display¶
Compared with examine, If we use display, the value will be printed each time the code is stopped, which is very convenient.
info display ---- get all the info of variables
display {var1 var2 var3} ---- print var1 var2 var3 each time.
display /i $pc ---- print where is pc at as asm.
delete display (%num) ---- delete all or %numth variable
disable/enable display (%num) ---- disable/enable %numth variable.
Layout:¶
use layout to display what you want, like source code .
layout regs
layout split ---- asm and src
layout asm
layout src
layout prev
layout next
focus name
(name = cmd|src|asm|regs|next|prev)
refresh
update
<C-l> refresh
<C-x> 1/2 ---- 1/2 window
<c-x> a ---- abort window
Else:¶
where ---- Print the current address and stack backtrace
list ---- see which line the code has examined and its contexts.
backtrace(bt) --- Print the backtrace of the entire stack.
TODO: frame 找段错误¶
Makefile¶
vim¶
杂项¶
用vim之前先在.vimrc中配置。
与系统剪贴板复制粘贴使用+y and +p.
<C-G> 显示文件信息
q: 显示历史命令 用<C-G>关闭(实际上和宏有关,有机会展开)
% 是找匹配的括号,在复制函数时很有用。
`` 偶然发现可以用这个方便的跳转
. 重复上一条指令
vim多文件编辑¶
怎么使用vim像vscode那样同时编辑多个文件呢?
$vim txt1 txt2 ---- 打开txt1和txt2
$vim -o txt1 txt2 ---- 打开txt1和txt2在同一个水平窗口里面
$vim -O txt1 txt2 ---- 打开txt1和txt2在同一个垂直窗口里面
<C-w> + w/hjkl ----- 切换窗口
vim itself¶
在编辑器内
:sp 将窗口水平分割成两个
:vsp 将窗口垂直分割成两个
:n下一个文件 :N上一个文件
:buffers ---- 显示当前所有正在编辑的文件
:buffer %n ---- 切换到第n个文件
:e txt3 ---- 打开txt3
ZZ ---- 保存当前文件更改
:wq ---- 保存所有文件更改
nerdtree¶
实际上,使用nerdtree插件更为好用
我用F2打开这个插件
打开以后,仍然可以用<C-w> + w/hjkl 在代码窗口和tree窗口切换
o在当前窗口打开文件、文件夹
t在新tab里打开文件、文件夹(文件夹就是新树了)
gt/gT在tab之间切换
s垂直打开标签页
r 刷新树
(当然,也可以用鼠标点。)
除此之外,nerdtree 当然也支持对文件的增删查找等。用它就不用到外部命令行新建文件了。基本上用 m 打开菜单栏就可以实现。
具体看这个链接:https://blog.csdn.net/weixin_37926734/article/details/124919260
Plugin introduction¶
vundle¶
vim +PluginInstall +qall
安装新的包。
ctags¶
cscope¶
我已经配置过:
<C-\> + %ch 等价于:cscope find %ch <name at cursor>
于是
:cscope find s # symbol: find all references to the token under cursor
:cscope find g # global: find global definition(s) of the token under cursor
:cscope find c # calls: find all calls to the function name under cursor
:cscope find t # text: find all instances of the text under cursor
:cscope find e # egrep: egrep search for the word under cursor
:cscope find f # file: open the filename under cursor
:cscope find i # includes: find files that include the filename under cursor
:cscope find d # called: find functions that function under cursor calls
在使用 cscope 时,可以输入 :cw 来打开 quickfix 窗口,来显示所有结果出现的位置。
在 quickfix 窗口切换不同的匹配项,可以输入 :cs cn 切换到下一个匹配项,:cs cp 切换到上一个匹配项。
当然,上下左右hjkl也可以。
YouCompleteMe¶
very powerful.
在.vimrc中配置, 配置去网上抄. c语言要装clang先.
个人配置的备忘:
选择补选项: 一是用上下方向键, 二是用<C-N>和<C-P>, 实际上原本默认是tab键选择的, 但是被我禁用了现在.
按了enter选中后是已经补全了, 但还是会剩下一个框. 不用管它继续编程即可.
linux¶
tools¶
tmux¶
会话¶
tmux可以用来打开多个terminal。
命令行下输入tmux, 打开新会话。
tmux new -s <session-name>可以给新会话取名字。
tmux info 会话信息
基本操作流程:
- 新建会话
tmux new -s my_session。 - 在 Tmux 窗口运行所需的程序。
- 按下快捷键Ctrl+b d将会话分离。
- 下次使用时,重新连接到会话
tmux attach-session -t my_session。 当然用tmux a可以快速连接上一个会话。
对tmux来说,最重要的快捷键就是<C-b>, 先输入这个,然后输入指令tmux才会响应。
Ctrl+b d ---- 分离当前会话。
Ctrl+b s ---- 列出所有会话。
Ctrl+b $ ---- 重命名当前会话
Ctrl+b : ---- 进入命令行模式
:kill-server 删除所有会话
:kill-session 删除当前会话
window¶
一个会话内,tmux可以包含多个窗口(感觉窗口和会话差不多,不赘述) 似乎还是窗口更方便切换啊。
<C-b> c ---- new window
<C-b> n ---- next window
<C-b> p ---- last window
<C-b> %num ---- to %numth window
<C-b> , ---- rename window
<C-b> [ ---- 进入复制模式(可以上下滚动屏幕),ESC 退出
窗格¶
也可以包含多个窗格
寻求帮助¶
Search The Fucking Web(STFW)
Read The Fucking Manual(RTFM)
Read The Fucking Source Code(RTFSC)
PA1¶
how to run nemu? enter nemu dictionary and make to complile, make run to run, make gdb to use gdb to debug.
框架介绍¶
TRM - Turing Machine.
存储器是个在nemu/src/memory/paddr.c中定义的大数组.
上面的代码定义了pmem,对应128M的存储空间
PC和通用寄存器都在nemu/src/isa/$ISA/include/isa-def.h中的结构体中定义.
寄存器有关的在全局变量cpu中,
包括cpu.pc程序计数器
和cpu.gpr[n]n表示第n个寄存器。
nemu/src/cpu/cpu-exec.c中有和指令执行相关的内容
cpu_exec(n)表示执行接下来的n条指令。
怎么开机¶
初始化nemu的代码在monitor.c中定义
前面都是些必要的准备工作,介绍一下init_isa()函数,在nemu/src/isa/$ISA/init.c中定义
void init_isa() {
/* Load built-in image. */
memcpy(guest_to_host(RESET_VECTOR), img, sizeof(img));
/* Initialize this virtual computer system. */
restart();
}
第一项工作就是将一个内置的客户程序读入到内存中.直接就用了memcpy这个函数,明快。
注意:
RESET_VECTOR是存放代码的固定内存地址。由于本次实验采用RISC-V,内存地址不从零开始,所以要用guest_to_host()函数来转换。
它将CPU要访问的内存地址转化成数组pmem中的偏移位置。
init_isa()的第二项任务是初始化寄存器, 这是通过restart()函数来实现的.它设置cpu.pc 的值并将0号寄存器置0.
题目回答 注意事项¶
在cmd_c()函数中, 调用cpu_exec()的时候传入了参数-1, 你知道这是什么意思吗?
看函数参数。是uint_32t类型的,是无符号整数。-1被看做无符号数,也就是2的32次方-1,就是运行这么多次。
表达式求值测试这里:
如何过滤除以零的表达式?
gcc 在编译的时候就会对除以0的表达式发生警报。在编译选项中加入-Werror将警告视作错误即可过滤。
如何获得无符号数的运算结果?
c语言默认数字是有符号的,在数字后面加u表示无符号数,如12333u。
我加入了逻辑运算通不过测试可能是什么原因?
注意C语言中, "||" 和 "&&" 是短路操作。你实现了吗?
负号怎么实现?
这里提供思路: 负号的识别看讲义. 负号的计算利用这个特征: 单元运算符只与最近的表达式(只能是括号或者是数字)相结合. 利用这个特点, 我考虑用栈, 若碰到单元运算符, 将之放入栈中. 另外再维护一个栈来记录下与这些单元运算符结合的括号或者数字的位置. 在递归出口时, 若是括号或者数字的情况, 比较该表达式所在位置和先前记录位置, 若相等, 说明栈中的运算符都是属于这个表达式的. 然后将运算符栈清空计算同时位置栈并弹出一个元素. 对了, 注意括号的情况. 有括号时, 将括号也压入栈, 弹出时弹到括号为止.
表述能力有限, 多包涵. 该思路本身有些麻烦, 不过通过了一些测试. 希望有更简单的思路.
做完PA1,你应该已经实现了一个简易的调试器。
PA2¶
C 语言库函数源码
https://stackoverflow.com/questions/5233514/where-to-find-stdio-h-functions-implementations
上面是 glibc 的实现。有好奇过 printf 是怎么实现的吗?看看上面的链接吧。
孙燕姿的学会真好听啊,很治愈。
做这个 PA 实验花的时间比预想的久,一个是我学得慢,riscv 看了一天,然后 make 怎么用看了一天,基本上每天只能过一点点进度,一天做显卡,一天做声卡;但是确实很有收获的,之前很少有机会看这么多代码。最大的收获就是对计算机系统的把握吧。
PA 2 这个实验花了应该有 100+ 小时吧,陆陆续续写了两个星期了
下面就以问题为导向来整理好了。
1. NEMU 中,一条指令是怎么完整执行的¶
好吧,就从这个必答题:一条汇编指令在 NEMU 中的执行过程开始说起。
只学过大计基的人也知道,指令的执行过程是取指、译码、执行,而 NEMU 正是这样的一个模拟器。
首先是开机, nemu/src/monitor/monitor.c 中做了各种初始化的工作
然后,开始执行你的程序。 执行有关的代码都在 nemu/src/cpu/cpu-exec.c 中。我们一层一层看下去就知道了(用 GDB 调试更清楚)。执行一条指令的函数是 exec_once(),它做了什么呢。
先看一个数据类型吧,看这个 Decode 结构的定义
typedef struct Decode {
vaddr_t pc;
vaddr_t snpc; // static next pc
vaddr_t dnpc; // dynamic next pc
ISADecodeInfo isa;
IFDEF(CONFIG_ITRACE, char logbuf[128]);
} Decode;
这个结构体存储了 pc 的信息。于是我们就这样更新 cpu.pc 这个程序计数器
nemu/src/isa/riscv32/inst.c 中。
取指¶
首先要取指。 s->pc 存储了当前要执行的指令地址,从这个地址读取指令。具体来说是这样,在NEMU中, 有一个函数 inst_fetch() (在 nemu/include/cpu/ifetch.h 中定义)专门负责取指令的工作. inst_fetch() 最终会根据参数len来调用 vaddr_ifetch() (在 nemu/src/memory/vaddr.c 中定义), 而目前 vaddr_ifetch() 又会通过 paddr_read() 来访问物理内存中的内容. 因此, 取指操作的本质只不过就是一次内存的访问而已.
另外, isa_exec_once() 在调用 inst_fetch() 的时候传入了 s->snpc 的地址, 因此 inst_fetch() 最后还会根据 len (即指令长度)来更新 s->snpc , 从而让 s->snpc 指向下一条指令.
译码¶
然后译码。接下来代码会进入 decode_exec() 函数, 来进行译码。译码,顾名思义就是翻译取出的指令,看对应的操作是什么。
在 NEMU 中,译码是通过模式匹配来实现的。要实现匹配,又定义了一个非常精妙的宏 INSTPAT 来定义。
格式是这样
例子如下
INSTPAT_START();
INSTPAT("??????? ????? ????? ??? ????? 00101 11", auipc, U, R(rd) = s->pc + imm);
INSTPAT("0000000 00001 00000 000 00000 11100 11", ebreak , N, NEMUTRAP(s->pc, R(10))); // R(10) is $a0
INSTPAT("??????? ????? ????? ??? ????? ????? ??", inv , N, INV(s->pc)); // invalid inst
// ...
INSTPAT_END();
如果你的指令满足某一条匹配规则,那么我们就可以根据这个规则将一串二进制 01 翻译成对应的执行操作了。
执行¶
译码完成了以后,相应的动作都是用 C 语言模拟的,我们执行这些动作就可以了。
更新 PC¶
上面执行完了以后,回到 exec-once 函数, 更新 pc 就结束了。
再之后的代码,就是打印出取到的指令的 16 进制表示及其反汇编结果的;源码很清楚,就不多说了,自己看吧。
tips
宏定义太复杂了,要绕晕了怎么办呢?编译器可以帮助我们。gcc 加 -E 选项可以只打印展开结果而不编译。
有两个宏定义的结构体,展开了就很清晰了: 一个就是存储寄存器和 PC 的情况,还有一个就是用来存储指令的结构体
根据 riscv 指令来一条条添加匹配规则,这就是 PA2 的第一部分了。这里就体现了 riscv 的优越性,只需要添加大约 40 条指令就可以通过所有的测试了,这是 x86 想都不敢想的事情。
上面就是一条指令完整的执行结果了。
NEMU 是什么?¶
NEMU 是一个模拟器,它模拟了真实计算机的硬件,从执行指令的 CPU 、内存到后面显卡、声卡等外设,都可以被它模拟出来。
2. AM 是什么?运行时环境是什么?¶
我写了一个 C 程序,要在 NEMU 上运行,怎么运行呢?我们要为程序提供它需要的运行时环境。运行时环境是一个抽象的概念,可以理解成“程序运行所需的各种需求的满足”。
在上一部分中我们实现了四十多条指令,意味着我们可以进行各种计算了,我们实现了一个“图灵机”。“图灵机”就是最简单的运行时环境:内存,结束运行的方式和运算的指令。
然后呢,如果我的程序的需求更多呢?它不满足于运算,它想要打印,它想要显示,想要接受键盘输入,等等,怎么办?我们要为它提供更丰富的运行时环境。
于是 AM 就应运而生了。AM 是一个为应用程序提供各种运行时环境的库。
AM 将程序运行的需求都收集起来,抽象成了统一的 API,应用程序有需求,直接调用对应的 API 就可以了。
其实,你也可以说,应用程序干嘛非得调库呢?我有需求,我自己码代码实现不可以吗?比如说,我想操控硬件,那我就直接写对硬件读写的代码呗,不行吗?
实际上,当然是可以的。但是,这样不麻烦吗?所以,AM 存在的最大意义就是为了抽象,而抽象是为了简单。我抽象出来,让应用程序不必关注底层的硬件,专注于实现自己的功能就可以了。
所以,原本的软硬件关系是这样的:
NEMU 提供硬件功能;应用软件直接执行,直接和硬件交互现在增加了一层 AM 抽象层:
NEMU 提供硬件功能;AM 抽象层负责和上层的软件和底层的硬件进行交互,屏蔽掉交互细节,只提供抽象接口给应用软件层;应用软件层不直接操纵硬件,只和 AM 抽象层进行交互。AM 中的 API,帮助实现了程序需要的运行时环境,于是将这些 API 称作 abstract machine,这就是 AM 库名称的由来。调用了这些接口的程序,称为 AM 程序。细细理解也是,这些接口实现,很像一个为程序运行提供各种东西的计算机。AM 库包含下面部分:
TRM 提供计算功能,IOE 提供输入输出功能,其他的还未涉及。
(2024年3月26日) 感觉自己上面有点啰嗦. 其实就是因为直接和硬件交互太麻烦了, 所以事先写好和硬件交互的函数再调用就不用这么麻烦每次都从零开始写了, AM 就是为了方便而产生的.
具体实现¶
运行时环境可以分为架构相关和架构无关。io 就是典型的架构相关的,不同 isa 对应的底层硬件不同,所以对每一种架构都要写一个对应的函数。还有一些库函数是架构无关的,一个实现就可以给所有的架构用了。
实现库函数这里都是苦力活,没什么好说的。就一个 bug 需要提一提,在实现 strcmp 的时候发现的,关于 char 的 bug。
char在编译时居然是默认被解释为无符号类型的,即unsigned char。应该是交叉编译导致的,因为 x86 的下编译是解释为有符号类型的(等待 difftest 验证)。解决方法是使用int8_t来明确类型。- 8 位无符号数相减得到的却是有符号数,然而结果用 (int) 扩展到 32 位后结果又变成了无符号数。这个特性不管是 x86 还是 riscv 都有。解决方法就是小心一点多做一步强制类型转换。 我现在发现这其实不是什么 bug,是这样的原因:有符号数和无符号数做运算(双目运算符的两边)时会转化为无符号数,所以在 a=1,b=2时,a-b==-1 和 a==-1u 都成立 这是因为 -1 被转化成了无符号数。
- 所以
<stdint.h>规避了很多歧义,建议使用。
3. AM 程序怎么构建,怎么在 NEMU 中运行?¶
讲义值得参考的部分:https://nju-projectn.github.io/ics-pa-gitbook/ics2023/2.3.html#rtfsc3
可以问一个更加具体的问题:在am-kernels/kernels/hello/ 下运行 make ARCH=$ISA-nemu run,make 到底做了些什么呢?
先看 AM 程序是怎么构建的吧。看 AM 的 Makefile 源文件,我可以看出来编译和链接的代码,并且可以根据 ARCH 这个命令行参数来选择不同的架构。选择的架构不同,就会选择不同的交叉编译工具,编译不同架构的代码。如果选择的架构是native,就直接用 gcc 编译成 x86 类型的文件,可以直接在 linux 主机上运行;如果选择的是riscv32-nemu,就会用riscv64-linux-gnu-gcc 来编译,并进行进一步处理,来使得程序可以在 nemu 上运行。
小问题
问题:我目前还没有搞清楚在 Makefile 中怎么规定编译链接的顺序。
勉强答:编译的先后顺序无所谓,链接的顺序是 ld 根据链接脚本 abstract-machine/scripts/linker.ld 来链接,but 这个文件我还是看不懂。
交叉编译
什么是交叉编译呢?在一个平台上将代码编译成另一个平台的程序就叫交叉编译。比如我们这里,就是在 x86 的 linux 平台下把代码编译成 riscv32 类型的文件。
如果要搞清楚 make 在做什么的话,可以利用 make 的 -n 选项来查看运行 make 会执行哪些命令。这里我们运行
输出的结果很长,我就不放了。 做的事情概括起来是:
- gcc 将 AM 实现源文件编译成目标文件,用 ar 将目标文件打包成一个库
- 通过 gcc 和 ar 将 klib 的实现编译打包成库
- gcc 把应用程序源文件
hello.c编译成目标文件 - 用 ld 根据链接脚本
abstract-machine/scripts/linker.ld, 将上述目标文件和归档文件链接成可执行文件,*.bin是镜像文件,将加载到 nemu 中运行,*.elf是对应的 16 进制文件,我们可以读取它获得相应的信息。 - run 选项对应的代码是
$(MAKE)i-C $(NEMU_HOME) ISA=$(ISA) run ARGS="$(NEMUFLAGS)" IMG=$(IMAGE).bin。很简单,是在 nemu 的主文件夹下编译构建出 nemu interpreter,并运行它。
接着,nemu 运行它的应用程序的过程:
- 打开 nemu 以后,nemu 在初始化的过程中会将即将执行的应用程序的镜像文件 (*.bin) 加载到内存 (pmem) 中。
- 开始运行程序后,第一条指令从
abstract-machine/am/src/$ISA/nemu/start.S开始, 设置好栈顶之后就跳转到abstract-machine/am/src/platform/nemu/trm.c的_trm_init()函数处执行. - 在
_trm_init()中调用main()函数执行程序的主体功能 - 从
main()函数返回后, 调用halt()结束运行
小问题
问题:编译构建 nemu 项目时,最后的项目名称 nemu-intepreter 哪里来的?我还没搞清楚。
4. IO 设备¶
NEMU 是怎么实现输入输出设备的模拟的?
看一看源码,一个设备是怎么注册的。首先规定好设备的大小,给设备接口分配一个所需的大小的空间(用 malloc 即可),然后规定好设备的映射地址,以及相应的回调函数,最后将空间、地址和函数等信息通过初始化函数存储起来,就完成了注册。
如果我注册了一个设备,当我访问这段物理地址的时候,就会跳转到对应 I/O 设备地址(就是上面 malloc 分配的额外的空间,而不再是 pmem 内存中了)。当我对这段地址读写时,可能会触发相应的回调函数,回调函数就是这个设备的“动作”了。比如串口的回调函数,就是打印写入的字符到标准错误流中。
更具体的,就 RTFSC 吧,源代码还是比较清楚的,讲义也很详细了: https://nju-projectn.github.io/ics-pa-gitbook/ics2023/2.5.html
声卡¶
最麻烦的就是声卡,需要软件硬件协同操作。
但是学到的也最多,实现了声卡了以后,理解就更深刻,在 AM 中寄存器的操作都还是软件层,AM 就是软件和硬件的桥梁,将相应的数据写到对应的内存中,然后硬件(NEMU)再进行处理,进行声音的播放。看到完整的 bad apple 还怪高兴的哈哈。
打开声卡前,最好关闭 trace 功能。
声卡很吃配置,打开声卡以后,超级玛丽完全玩不了了。(显卡还有十几帧的)。
另外,不要老是挂起虚拟机。正常的指令执行速度是每秒两千万条,有的时候性能降低到每秒八万条,打字都卡,就赶紧关机重启吧。
二次元是这样的:
................................................................................
..............................................X.X.X.............................
.............................................XXXXXXXXX..........................
..............................................XXXXXXXXX.XXXXX...................
............................................XXXXXXXXXXXXXXXXXXX.................
........................................X.XXXXXXXXXXXXXXXXXXXXX.................
........................................XXXXXXXXXXXXXXXXXXXXXXXX................
........................................XXXXXXXXXXXXXXXXXXXXXXXXX...............
.......................................XXXXXXXXXXXXXXXXXXXXXXXXXXX..............
........................................XXXXXXXXXXXXXXXXXXXXXXXXXXX.............
...........................................XXXXXXXXXXXXXXXXXXXXXXXX.............
............................................XXXXXXXXXXXXXXXXXXXXXXX.............
.............................................XXXXXXXXXXXXXXXXXXXXXX.............
..............................................XXX.XXXXXXXXXXXXXXXXX.............
..............................................XXXXXXXXXXXXXXXXXXXXXX............
........................X.X.X.X...............XXXXXXXXXXXXXXXXX.X.X.............
.......................XXXXXXXXX...............XXXXXXXXXXXXXXXX.................
......................XXXXXXXXXXX...........X.XXXXXXXXXXXXXXX.X.................
.......................XXXXXXXXXXX.X.......XXXXXXXXXXXXXXXXXXX..................
........................XXXXXXXXXXXXXXX.X.XXXXXXXXXXXXXXXXXXXX..................
.............................XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX..................
............................XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX...X.X...........
.............................XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX.X............
............................XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX...............
............................XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX..............
5. 杂项¶
ftrace 真的是要老命了,纯苦力活。
读取 ELF 文件?问互联网、问手册、问 GPT 吧。简单的说,利用 fread fseek 将文件里的信息读取到 <elf.h> 中定义的结构体里面,就成功了。我会不会简单介绍一下 ELF 的结构呢?会的。
怎么判断 riscv 中何时 call、何时 ret?call 和 ret 都会离开当前函数体。先判断 call,如果下一条指令地址是一个函数头,就一定是 call,反之就是 ret。
而且 ftrace 做完以后还引入一个新 bug:我关闭调试信息选项以后,编译不通过了是几个意思???(其实可以理解,因为关闭调试选项意味着没有了任何信息,导致读入的都是无效的字符,所以导致编译器报未初始化警告)
想尽可能把实验的记录写清楚点,但是真的太花精力了,睡觉!
然后还有一点,NEMU 的性能真的很低,不要期望可以流畅运行多好的程序。
上面的NEMU只能运行一个程序。如何实现多程序同时运行?虚拟内存:PA4 的内容
6. makefile 的各种问题¶
- mainargs 是怎么传参到程序的。我遭遇了 bug,前几天能成功传参的,现在突然不行了.
- https://www.cnblogs.com/nosae/p/17066439.html#%E7%90%86%E8%A7%A3mainargs
- 别人直接都把答案写在博客里了,还是要自己独立完成啊。
- CFLAGS += -DMAINARGS=\"$(mainargs)\" $AM_HOME/scripts/platform/nemu.mk
PA3¶
PA3.1¶
PA3.1 主要讲的是异常,这里如笼统地将中断和异常两个概念混为一谈, 那么这个概念在单片机中已经学过,可以很不准确地将之理解为另外一种“函数”的调用。
为了支持异常,riscv 是引入了特权级指令(ecall/mret/csrrw/csrrc 等等)和控制状态寄存器 CSR(mepc/mstatus/mcause/mtvec 等等)。为了实现异常,硬件层面要额外加上这些指令和寄存器。
处理异常的过程¶
然后看看处理“异常” 究竟发生了什么吧。
在我使用了 ecall 自陷指令来主动发生异常后,硬件层面所做的事情如下:
- 将当前PC值保存到mepc寄存器
- 在mcause寄存器中设置异常号
- 从mtvec寄存器中取出异常入口地址
- 跳转到异常入口地址
然后就对异常进行处理,首先要保存原程序的状态,然后再进行下一步操作,比如在单片机中可以进行一次 AD/DA 的操作,在操作系统中可以处理错误等等。根据异常的种类来决定是否返回源程序。
如果返回原程序,那么就先恢复原程序的状态,然后使用 mret 指令,取出 mepc 中的地址放入 pc 中,从异常状态中返回。
程序的状态,更确切的说,可以用“上下文(context)”这个概念描述。AM 也有上下文管理的 API,名为 CTE。上下文管理主要需要两个信息,一个是触发异常的事件 event,还有就是程序的上下文 context 了。程序的上下文包括各种寄存器的信息。CTE 的各种 API 都在 cte.c 中,包括 cte_init,__am_irq_handle,yield 等等。
yield test 发生了什么¶
上面说完了异常处理的过程,那么下面就回答一下一个必答题:在 yield test 中究竟发生了什么事情?
首先是在 cte_init 函数中初始化。这个函数做两件事情:1. 在 mtvec 寄存器中设置异常入口地址,2. 设置回调函数(异常处理函数)。注意这句代码:
也就是说,异常向量 mtvec 的地址就是 __am_asm_trap 这个函数的入口。
然后经过一些无关紧要的操作后,调用 yield 函数。yield 函数里面就是内联汇编代码,使用 ecall 指令来进行自陷操作。ecall 指令让程序跳转到异常入口,即 __am_asm_trap 的起始地址。__am_asm_trap 是 trap.S 中的汇编代码。做的事情其实就是把寄存器信息压入到栈中保存,然后进入 __am_irq_handle 这个函数中,调用之前的初始化设置的回调函数,完成异常处理(这里就是打印 y 这个字符),然后回去恢复寄存器信息,最后 mret 回到原来的位置,就完成了一次异常处理。因为是在一个无限循环中,所以会不断的打印 y。如果没有在循环中, 那打印一次 y 程序就结束了.
yield test 就这样走完了它的全过程。
等等,还有一件事!__am_irq_handle 中上下文结构体指针 c 是什么时候来的,什么时候赋值的?都走完了也没见它的踪影啊。
如果只看 C 语言代码的话,是永远也找不到答案的。答案在汇编代码 trap.S 中。__am_irq_handle 是在 trap.S 中被调用的。汇编语言的函数参数是怎么确定的呢?关键就是调用函数前一句代码,mv a0, sp,这是汇编语言的传参。看一下 riscv 的手册也可以知道,a0 寄存器储存函数的第一个参数。__am_irq_handle 的第一个参数就是结构指针 c,所以传入的参数就是栈地址 sp。结构体有这样的性质:如果某个地址开头正好是结构体的地址,并且写入顺序和结构体的定义顺序一致,那么就相当于向一个结构体写数据。所以,赋值的过程,在我们将寄存器压入内存的时候就已经完成了。这就是这个问题的答案,也是 PA 的其中一个问题,要求我们按规定的顺序来定义 context 结构体的原因。
总结:PA3.1 主要的坑一个是内联汇编不熟悉,还有一个是汇编语言已经忘记得差不多了,所以完全没有看出来 mv a0, sp 是函数参数的赋值。非常感谢:https://www.cnblogs.com/GrootStudy/p/17039807.html 给了我很大的启发。
PA 3.2¶
PA 3.2 主要的任务是实现了系统调用,然后可以用 nanos-lite 这个简单的批处理系统加载一些应用程序。
要实现上面的功能,首先就是要先将应用程序加载到对应的内存中。这里我想到一个小问题,为什么 NEMU 内存可以直接通过绝对地址访问?比如 "0x83000000" ?
这个问题其实挺简单的。一般来讲代码里的变量、数组的地址都是通过编译器来分配的。但你直接写一个绝对地址,访问这个地址也是可以的,最后编译器转化成底层的汇编代码后,那些底层的汇编代码就会访问你写的绝对地址。paddr_read、paddr_write 这些函数都是在模拟汇编指令的时候调用了。
然后就是实现系统调用了,首先对 AM 进行一些修改,使得我们的批处理系统能够分辨是自陷事件还是系统调用事件,然后根据不同的系统调用,进行底层的 AM 实现就可以了。我们现在实现的系统调用有:yield 调用进入自陷,write 调用进行输出,exit 调用退出程序,sbrk 调用分配内存等。
下面我们就完完整整地讲解一下 hello 这个测试程序的来龙去脉吧。目前我也还有些没完全搞清楚,期待补充。
首先得解释一下,navy 项目中的程序都是依赖于 newlib 库来运行的,newlib 是一个为嵌入式系统提供的 C 库。hello 程序中的 printf 函数可能与 AM 项目中的函数重名,但是具体的实现是在 newlib 中实现的,并且逻辑也不同。下面会详细说明。
用户程序从哪里开始的呢?好吧我承认我没看仔细讲义里有的。用户程序的入口位于 navy-apps/libs/libos/src/crt0/start.S 中的 _start() 函数,_start() 函数会调用 navy-apps/libs/libos/src/crt0/crt0.c 中的 call_main() 函数, 然后调用用户程序的 main() 函数, 从 main() 函数返回后会调用 exit() 结束运行。怎么跳转到用户程序的入口呢? Nanos-lite 在加载好用户程序后,返回用户地址入口 entry,然后 ((void (*)())entry)(); 就跳转了。
hallo 程序中涉及了上面除了 yield 外所有的系统调用。首先是 write 函数,查看一下 write 函数的源代码就知道,write 调用了 _write_r 函数,_write_r 函数调用了 _write 函数,_write 函数调用了我们的系统函数 _syscall_。上面都是应用程序层面的实现,一直到 _syscall_ 才到底层的实现。_syscall_ 函数将异常状态号和输入参数设置好以后,就执行 ebreak 指令,ebreak 指令跳转到之前设置的异常入口地址 __am_asm_trap,然后是 __am_irq_handle,然后是回调函数 do_event,do_event 识别是 syscall 类型的事件,然后执行 do_syscall 函数,do_syscall 识别是 write 系统调用,执行 sys_write 函数,在这个函数里终于通过 putch 函数,将字符一个个输出到串口。
然后介绍 printf 函数。printf 的实现就非常复杂了。具体可以看这个链接:https://www.cnblogs.com/DF11G/p/14750056.html。可以简单的理解为,先通过 sbrk 系统调用获取内存,然后再通过上面讲解 write 系统调用输出。而 AM 中的 printf,本质上就是直接通过 putch 输出格式化的字符串。所以两者还是非常不同的。
程序结束后,就会通过 exit 函数退出。(原来的 hello 程序是死循环,我把循环改了)。exit() 函数层层跳转后,就是我们的 exit 系统调用。另外,我这里有一个 bug 没有解决,就是在调用 printf 函数后,系统的退出值就不是 0,但是可惜很难看出是哪方面的原因,但是总而言之,与我无瓜,因为即使是 sbrk 没有实现的情况下,结果也如此。更新:完成 PA3.3 的文件系统后,这个 bug 突然消失了,又可以完美退出了,可怕。
接下来我们来看一下 sbrk 系统调用吧。newlib 库中的 malloc 函数最终就是调用了 _sbrk 函数。比如我们可以看一下 libgross 库中 ARM 体系的实现。(libgross 是 newlib 库中自带的底层实现,但是可惜没有 PA 系统的底层实现,哈哈)
void * __attribute__((weak))
_sbrk (ptrdiff_t incr)
{
extern char end asm ("end"); /* Defined by the linker. */
static char * heap_end;
char * prev_heap_end;
if (heap_end == NULL)
heap_end = & end;
prev_heap_end = heap_end;
if ((heap_end + incr > stack_ptr)
/* Honour heap limit if it's valid. */
|| (__heap_limit != 0xcafedead && heap_end + incr > (char *)__heap_limit))
{
errno = ENOMEM;
return (void *) -1;
}
heap_end += incr;
return (void *) prev_heap_end;
}
之前说没理解, 现在感觉没有什么不好理解的, 分配内存就是这么做的, (可能是写了好几次的关系). 另外, &end 地址是程序数据段的末尾地址, 即堆区的起始位置, (去看一下程序结构里的图就明白了). 堆的内存边界通常被称为 program break. 调用 sbrk() 的过程, 就会更新 program break. (即上述代码中的 heap_end). 看下图:
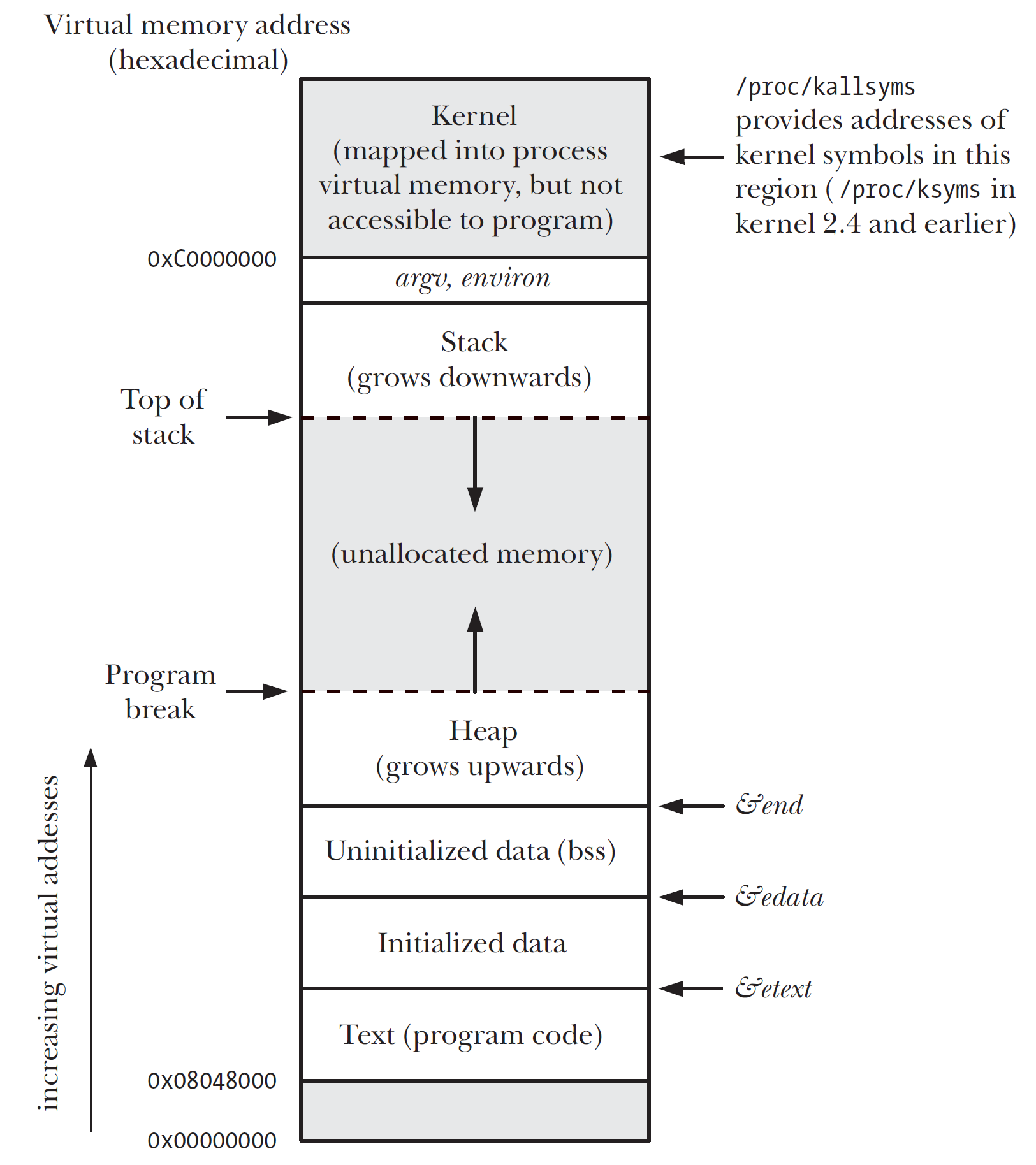
上面基本就是 PA3, part 2 了。总结一下,在 NEMU 硬件上,我们实现了 AM 接口,然后写了一个 AM 程序 nanos-lite,在 nanos-lite 上,我们运行应用程序。应用程序不能直接操控底层,而是通过系统调用来和底层交互(对应用程序来说,AM 也算是底层了,毕竟是直接和硬件交互的库)。
学而不思则罔,思而不学则殆,PA3.2 基本上完成了,但是一些关于程序的知识仍然不了解,比如堆的机制。系统调用的过程还需要好好理解,elf 文件的结构要整理了。PA3 和前面最大的区别就是多了一些我没学习过的理论知识需要补充吧。(补充, 这里说的问题基本都整理完毕 2024年3月30日)
PA 3.3¶
PA3.3 首先是实现了一个简单的文件系统,实现了 open、read、write、lseek、close 系统调用,这样我们就可以进行文件操作了。在 linux 中,有一个说法是“一切皆文件”。这是因为 IO 接口也被抽象成文件了,我们进行 IO 的过程就被抽象成文件读写的过程,上层 API 无需改动,只要根据文件类型更改底层调用的读写函数就可以了。基于这个逻辑,我们很快就实现了操作系统的各种 IO 接口,比如输入输出,键盘,显存,时间等等。完成这些接口以后,我们就可以运行各式各样的应用程序了。
当然理论如此,实践的时候总会碰到各种各样的问题。比如说,一开始提供的多媒体库是 NDL 库,它的实现是直接进行系统调用。然而,对于较为复杂的程序,直接用它编程仍然比较难,所以我们要提供更加上层的运行时环境,这里就是 SDL 库,在 SDL 库的实现中调用 NDL 库。具体的编程过程就不细说了,有些繁琐,调试了很久才基本完全跑通,主要还是要仔细阅读手册和讲义内容。
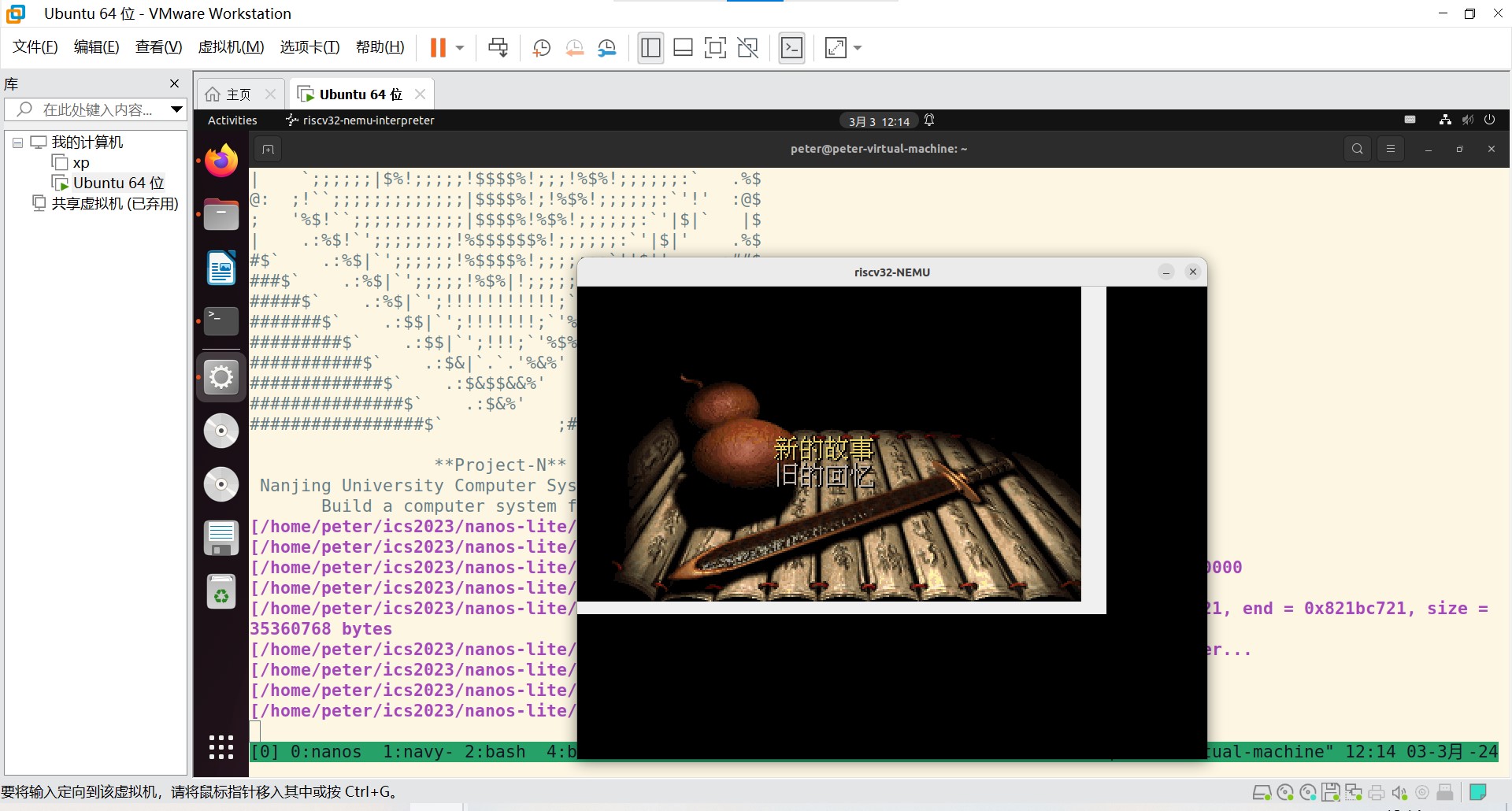
上面都是一些概括,说一个稍具体些的例子吧。讲义里面有一个问题是:仙剑奇侠传的代码如何从 mgo.mkf 文件中读出仙鹤的像素信息, 并且更新到屏幕上?
仙剑奇侠传的代码很复杂,而且函数也是一层一层套的。但是到底层,调用的仍然是我们实现的 SDL 库函数来进行绘图和更新屏幕,SDL_UpdateRect(),这个函数调用的是 NDL 库的函数 NDL_DrawRect()。NDL_DrawRect() 调用 write() 函数,将像素数组 pixels 写入虚拟文件 /dev/fb (也就是帧缓冲 frame buffer)中。这是上层的内容,即应用程序看到的内容。
然后操作系统 Nanos-lite 看到的内容是,数据写入 /dev/fb,要调用对应的写函数。就 C 语言具体实现来说,利用函数指针就可以轻松地根据文件的类型来选择调用的函数了。那么这里的写函数是要更新屏幕的,所以调用 AM 程序的 IO 接口 io_write() 函数就可以了。
从硬件 NEMU 的角度看,调用 IO 接口,本质上还是对某一个地址进行读写操作。然而,不同的是,这些地址在底层实现上进行了映射。如果读写到这些地址,不是对真实的物理内存进行读写,而是对映射的 IO 地址进行读写。读写完后,新像素就更新到了屏幕上。
上面就是自顶向下的应用程序进行屏幕更新的全过程。
仙剑奇侠传运行:
TODO: 搞清楚 native 和 riscv32-NEMU 的区别。(链接的库有哪些不同?)
TODO: open 和 fopen 的区别(文件系统)
TODO: malloc 和 free 的源代码实现。
PA4¶
PA4.1 多道程序¶
实现了命令行参数的传递, 内核进程和用户进程切换运行, 以及 busybox 来实现一些 shell 指令.
PA4.2 分页¶
首先虚拟内存的知识点已经整理到了相应的博客里面.
实现了虚拟内存转物理内存. 首先是操作系统在启动时将相关信息写入内存(虚拟页到物理页的映射关系). 后面翻译时, 拿到一个虚拟地址, 只需将其所在的虚拟页转化成物理页, 就迎刃而解了, 因为页大小相同, 所以偏移量也是相同的.
其实虚拟内存还是挺简单的, 哈哈. 但是实际编写代码, 还是会碰到各种各样的问题.
PA4.2 调了 3 天 bug
碰到的 bug 如下:
- bss 段忘记清零
- 将程序写入物理页时, 没有考虑偏移的情况(即程序段的虚拟地址并不是从页开始, 那么写入物理段时也应当有一个偏移).
- 最愚蠢的. 有时调试要切回 PA4.1, 那个时候程序是链接到 0x8300 0000 的, 而完成虚拟内存后, 链接到的地址是 0x4000 0000 的. 然后切回 PA4.2 的版本, 忘记 make update 了, 结果还是跑老程序. 而 0x8300 0000 的部分是会被分配出去的, 数据会被修改, 就会导致错误.
- 现在执行新程序(如用 nterm 打开仙剑奇侠传)会导致错误(我一开始还以为是环境变量的问题). (PS, 不要让 Hello 打印居然就不会引发错误). 看了一下, 是 PA4.3 的内容, 到那时去探究.
PA 4.3 栈切换¶
Note
时钟中断很简单就不展开讲了.
首先要回答上面的问题 4, 为什么执行新程序, 或者两个用户进程同时运行会导致错误. 这是因为目前为止, 在触发异常时, 我们都是将上下文储存在用户栈上的. 这就导致了切换上下文时我们储存在 PCB 中的地址是虚拟地址. 举个例子, 假设我们是要从进程 A 切换到进程 B. 切换完的第一步就是要 __am_switch(cB), 将 satp 设置成 cB.pdir. 然而, 我们现在还在 A 的虚拟地址空间中, 只能按照 A 的规则转换 cB 的虚拟地址, 这就导致了我们无法找到真正的 cB.pdir, 再后面, 对进程 B 的地址转换也就无从谈起了.
假设是内核线程 A 和用户进程 B 同时运行, 再由 B 打开 C, 也会碰到类似的错误. 在切换到 C 时, satp 不是 C 的地址空间, 因此无法正确映射.
要解决上面问题的方法, 其实说起来非常简单(注意: "说起来"和实现总是有差的): 在保存上下文时, 将上下文储存在内核栈上. 这样, 储存在 PCB 中的上下文的地址均是实际的物理地址, 也就不存在映射不映射的问题了.
具体的实现, 参照讲义的伪代码就可以了:
void __am_asm_trap() {
if (ksp != 0) { // ksp is global
c->usp = $sp; // usp should be in Context
$sp = ksp;
}
c->np = (ksp == 0 ? KERNEL : USER); // np should be in Context
ksp = 0; // support re-entry of CTE
// save context
__am_irq_handle(c);
// restore context
if (c->np == USER) {
ksp = $sp;
$sp = c->usp;
}
return_from_trap();
}
碰到的 bug 如下:
- 写完栈切换的汇编代码后, 发现内核和用户栈切换会导致错误. 最后 sp 的值是 fffffffx 这个问题是内核 Context 没有初始化, 所以返回后 sp 变为 0, 下次调用函数时减去某个值, 就得到上面那个不合法地址了.
- 用户栈之间切换导致错误. 选择两个最简单的进程, 只打印某些字符. 但是每次或是打印错误的字符, 或是直接错误. 并且逐步调试, 错误的地方都是 serial_write 函数. 并且, yield 放在 putch 之前就会报错, 然而之后就不会, 所以是 yield 触发异常之后导致了某些问题. 再进行逐步调试, 比较两种情况下的 yield 触发前和触发后的情况, 发现是地址映射寄存器 satp 改变了. 所以是 satp 的问题, yield 以后 satp 没有变回来, 导致后面的地址映射错误. 问题是在 am_irq_handle 中没有保存 satp 的值. 现在实现了栈切换, 无脑保存即可. 修改逻辑以后, 就可以成功运行两个用户进程了.
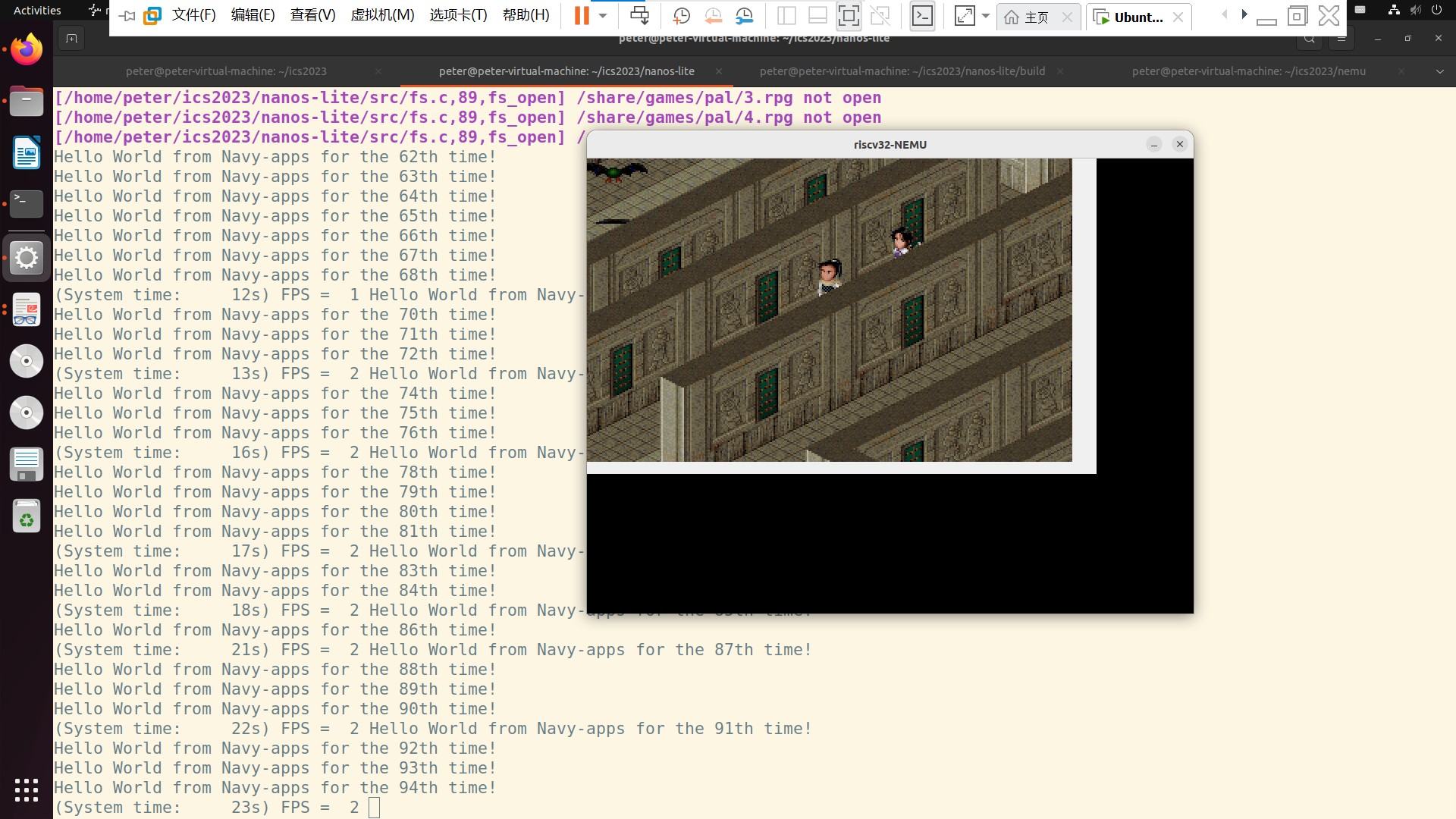
上面是 Hello 线程和仙剑奇侠传的线程同时运行.
最后是台前调度的功能, 本来以为完不成了, 没想到我居然这么聪明, 看出了问题所在啊. 首先, 明面上的现象是, 程序能否正确运行居然是和 init_proc 函数中 context_uload 的顺序有关, 只有前台程序 (fg_pcb) 恰好是最后一个 context_uload 的才能正确运行. 但是理论上说, 程序加载进不同的 PCB, 当然都可以使用, 和加载顺序当然是无关的. 这是一个很匪夷所思的问题, 直接思考可能会想是否是后面的 PCB 会否覆盖了前面的 PCB. 但是, 排查了一下, 似乎很难验证这种现象.
所以, 要找错误, 就要开始调试. 打开 NEMU 的 trace, 发现不管是前面的情况, 还是正确运行后更改进程, 错误的地方都是 am_asm_trap 中 mret. 在 mret 后, 原本能解码的虚拟地址突然就不能解码了. 因为都是在内核中出问题, 并且返回地址是虚拟地址, 这意味着是应用程序申请系统调用时出了问题. 打开 strace, 发现都是在 9 号调用中出的问题, 而 9 号调用是 brk, 内存申请调用. 内存申请调用时, 唯一可能修改虚拟地址的映射的, 就是 mm_brk 中的 map 函数. 之前一直正确的 map 函数能出问题, 的确没有想到. 看一下它的逻辑, 是物理地址连续时, 能正确映射, 然而不连续就会覆盖前面的地址表. 所以就导致了为什么最后一个程序能正确运行, 因为地址映射是连续的. 修改了 map 函数的错误逻辑以后, 就可以开心滴进行前台调度了.
其实调试的过程虽然很煎熬, 而且往往排查一下午甚至一天, 最后导致错误的, 只是一小句代码. 但是逻辑推理的过程, 由现象找到本质, 找到精确的错误点, 并解决它, 是非常有成就感的.
如下图所示, 切到 bird 游戏后又切到仙剑奇侠传.
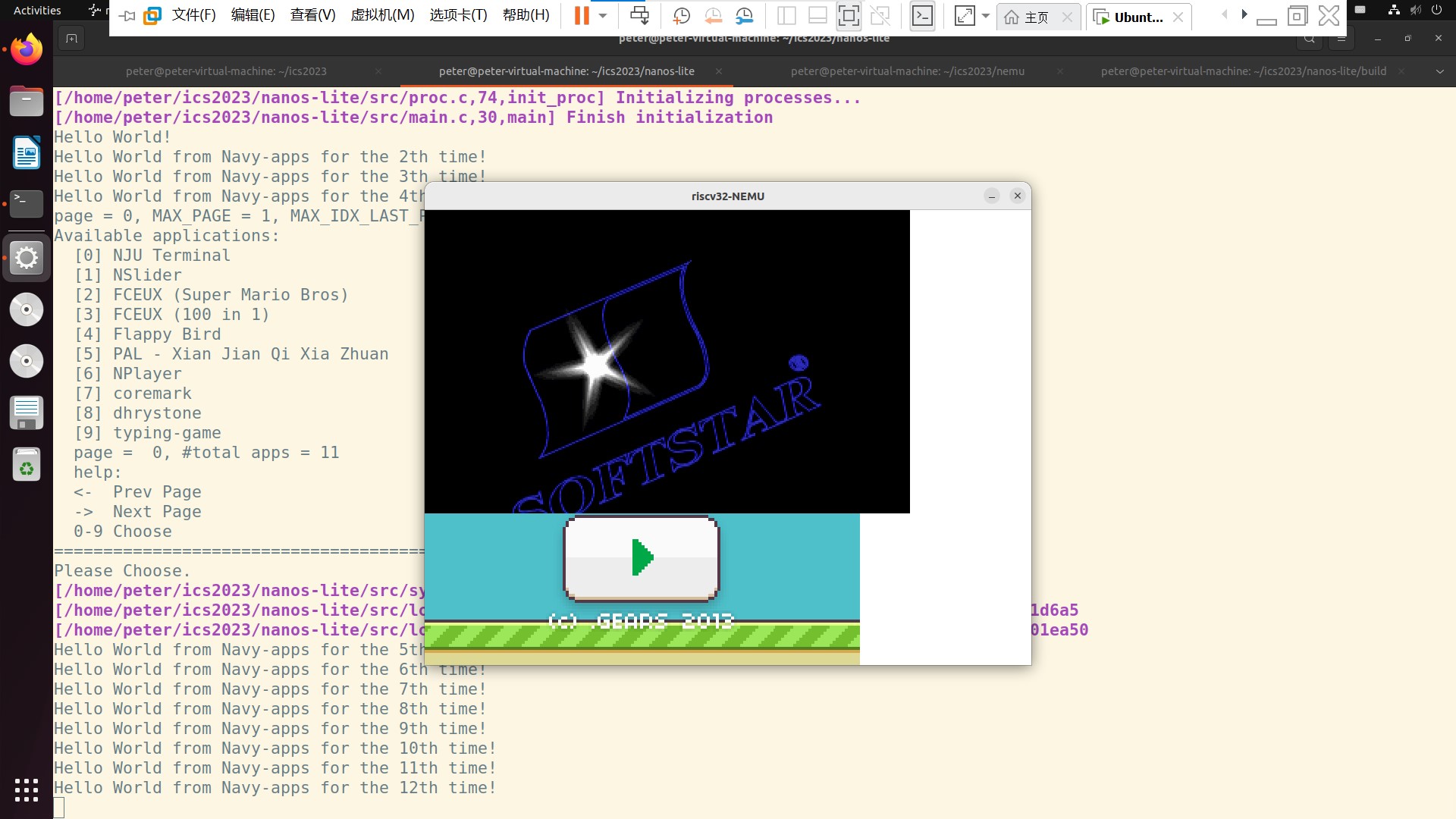
必答题:最后总结一下,仙剑奇侠传怎么同时和 hello 用户程序分时运行?
以 hello 程序切换为例:每一条指令结束,NEMU 的 cpu_exec() 函数会检查 CPU 的 INTR 引脚是否被拉高,是则有时钟中断请求,若此时 CPU 允许中断,则会进入设置好的中断处理程序 trap.s。在其中,nanos-lite 会将 hello 进程的上下文保存到内核栈中,进入 __am_irq_handle() 函数,调用之前的回调函数 do_event(),再到 schedule() 函数切换到仙剑奇侠传进程的上下文。回到 trap.s 恢复这个上下文,将栈指针转移回用户栈,最后 mret 指令之后,就切换到了仙剑奇侠传的代码继续执行。
那么现在, 我就完成了 PA 的所有必做项目. (虽然选做还留了一堆坑)
整个 PA 全部做下来, 对于我这样的新手来说, 大概需要将近 300 个小时. 也陆陆续续做了快半年. 做这个 PA 不仅仅只是做了一个项目, 还顺带学习了一堆东西, 比如, vim, make, shell script, 以及这个笔记网站, 还有各种知识, 比如程序结构, 虚拟内存等等. 讲义里面老是强调状态机的事情, 做前面的内容还不以为意, 但是到了 PA4, 过程的复杂度就陡然上升了, 要模拟运行的过程把我的草稿纸都耗完了, 这才又回想起来.
非常感谢 PA, 那么 PA 就暂时告一段落了, 再见!