存储器层次结构¶
本篇主要是对 CSAPP 第六章的整理.
1. 存储技术¶
1.1 RAM¶
RAM(Random-Access Memory), 随机访问存储器. RAM 有两类, SRAM(静态) 和 DRAM(动态). SRAM 更快, 用来作为高速缓存存储器. DRAM 用来作为主存和图形系统的帧缓冲区.
RAM 如果断电就会丢失信息, 因此称为易失性存储器. ROM 则是非易失性存储器, 包括 PROM/EPROM/EEPROM 等. 存储在 ROM 设备中的程序称为固件, 比如 BIOS, 这是因为(曾经的) ROM 通常是不修改的.
CPU 可以直接和 DRAM 主存进行数据的交互. 如下图所示:
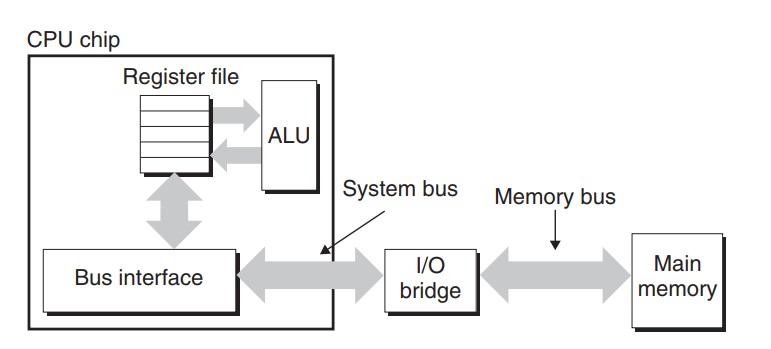
执行 movq A %rax 时, CPU 先将地址 A 放到系统总线(system bus)上, I/O 桥将信号传递到内存总线(memory bus). 主存接受到内存总线上的地址信号, 从内存总线读地址, 读取出对应的数据, 将数据 x 写回内存总线. I/O 桥将内存总线信号翻译成系统总线信号, 被 CPU 接收. CPU 从系统总线上读到数据, 将数据复制给寄存器 %rax. 以上就是内存交互的过程.
1.2 磁盘¶
磁盘可以分为机械硬盘和固态硬盘. CPU 访问磁盘的过程就是 CPU 与 IO 外设交互的过程.
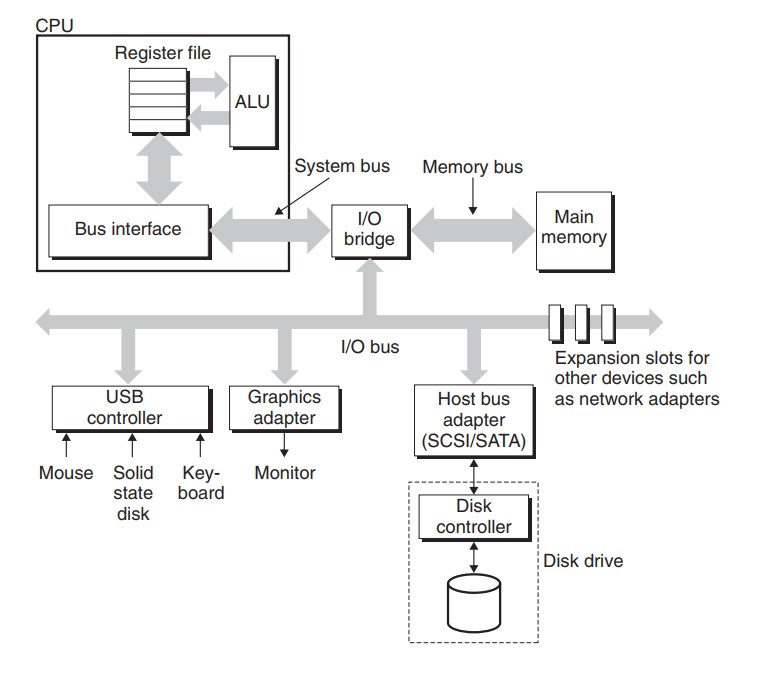
显卡/鼠标/键盘/磁盘这样的输入输出设备, 都是通过 IO 总线连接到 CPU 和主存的. IO 总线支持很多种类的第三方 IO 设备, 比如上图中的 USB(连接鼠标和键盘), 显卡(连接显示器), 主机总线适配器(连接磁盘), 还有我哪里过适配器等等.
CPU 使用内存映射 IO 来向 IO 设备发送命令. 使用内存映射 IO 的系统, 地址空间有一块地址是为与 IO 设备通信保留的. 当访问这个地址时, 不会真的访问物理地址, 而是和对应的 IO 设备进行交互. 这个我们在 NEMU 中已经实现过了.
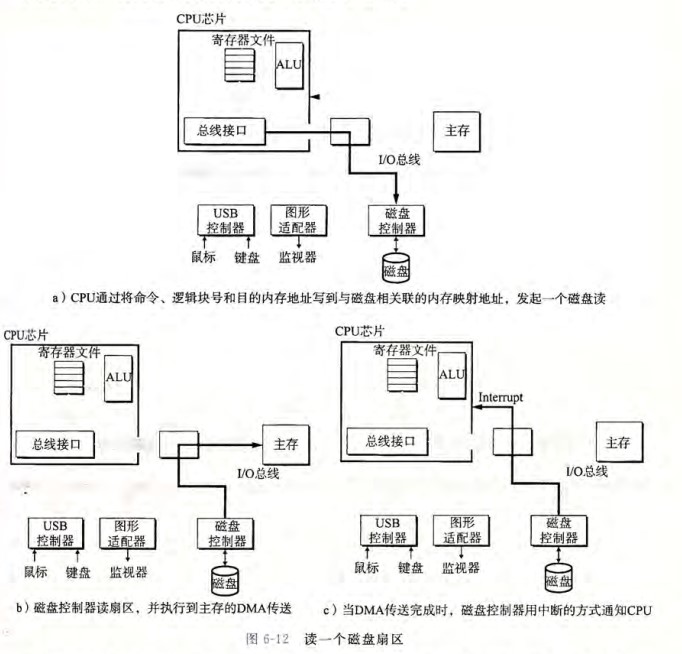
举个例子, 如果磁盘映射到地址 0xa0, CPU 要读取磁盘内容, 首先 CPU 要将命令/逻辑块号/目的内存地址写到这个映射地址中. 由于磁盘的读写非常慢(16ms, 1GHZ 的处理器时钟周期 1ns), CPU 不会等待磁盘, 而是继续执行下面的指令, 而磁盘则读取对应扇区的数据, 并将数据不通过 CPU 就直接传送到主存中. 这种技术叫 DMA(direct memory access, 直接内存访问). DMA 传送完成后, 磁盘再发送一个中断信号给 CPU, 让 CPU 从主存中读取.
2. 局部性¶
局部性是指程序在执行过程中, 引用的存储位置总是倾向于邻近最近引用过的位置. 局部性可以分为两类:
- 时间局部性(Temporal Locality):如果一个内存位置被访问,那么在近期它很可能会被再次访问。
- 空间局部性(Spatial Locality):如果一个内存位置被访问,那么在近期它附近的内存位置很可能也会被访问。
具体来看一些例子:
sum 变量被多次使用, 所以它有良好的时间局部性. 但是它是个标量, 所以没有空间局部性. 变量 v 是按照内存中的顺序读取, 空间局部性良好, 但是没有时间局部性, 因为每个元素只被访问一次. 总体而言, 这个函数有着良好的局部性.
一个连续变量每隔 k 个元素进行访问, 称为步长为 k 的引用模式. 上面的函数步长为 1. 一般来说, 步长越长, 空间局部性越差. 所以上面的函数空间局部性很好.
下面就可以看出差距了:
int sumarrayrows(int a[M][N])
{
int i,j,sum=0;
for(i=0;i<M;i++)
for(j=0;j<N;j++)
sum+=a[i][j];
return sum;
}
int sumarraycols(int a[M][N])
{
int i,j,sum=0;
for(j=0;j<N;i++)
for(i=0;i<M;j++)
sum+=a[i][j];
return sum;
}
尽管看上去是一样的, 但是对于多维数组, C 语言是按照行顺序来储存内存的, 导致第一个函数的步长是 1, 而第二个函数的步长是 N, 使得按列求和的局部性很差. 局部性越差, 会导致缓存的命中率越低, 导致程序的速度被大大减慢.
总体而言:
- 重复引用相同变量的程序有着良好的时间局部性.
- 对于有着步长为 k 的引用模式的程序, 步长越小, 空间局部性越好.
- 对于取指令来说, 循环的时间和空间局部性较好. 循环体越小, 迭代次数越多, 局部性越好.
3. 存储器层次结构¶
从硬件层面看, 目前的存储技术, 速度越快, 成本越高, 容量越小, 并且 CPU 和主存之间的速度差距越来越大. 从软件层面看, 编写良好的程序倾向于有着良好的局部性. 这些原因, 导致了我们使用存储器层次结构来组织存储器系统. 寄存器可在一个 CPU 时钟周期内被访问. CPU 和 DRAM 主存之间的速度差距越来越大, 因此中间有几个基于 SRAM 的缓存存储器, 只需几个 CPU 时钟周期就可以访问. 主存可以在几十到几百个时钟周期被访问. 后面就是很慢速的磁盘甚至服务器了.
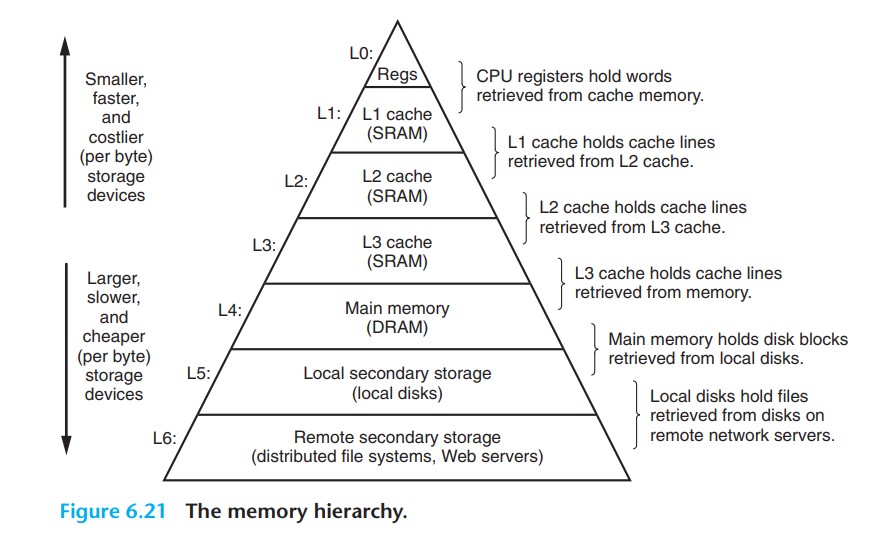
3.1 缓存技术¶
缓存, cache, 是一个小而快速的存储设备, 作为存储在更大更慢的设备的数据对象的缓冲区域.
存储器层次结构的基本思想就是, 层次结构的每一层都缓存来自更低一层的数据对象. 第 k+1 层的存储器被划分成连续的数据对象组块, 每个块都有唯一的地址或名字. 第 k 层的存储器也被划分成较少的块的集合, 每个块的大小和第 k+1 层的块的大小一样. 数据以块大小为传输单元, 在各个层次对之间复制. 注意, 各个层次对之间有不同的块大小. 层次结构中的较低层, 为了弥补较长的访问时间, 倾向于使用较大的块.
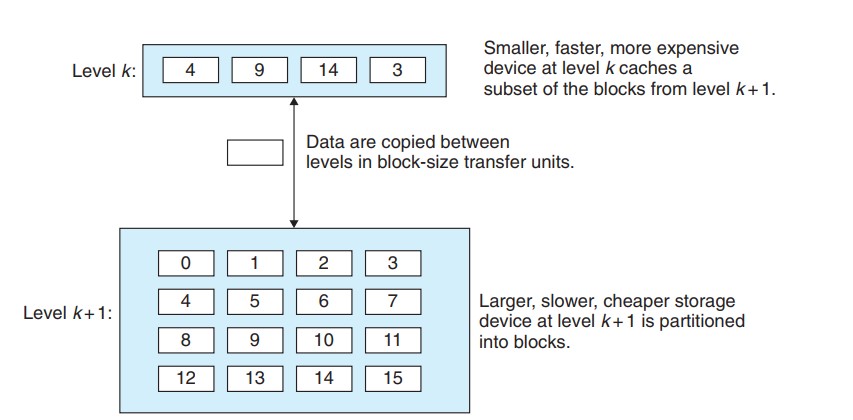
当程序需要第 k+1 层的数据对象 d 时, 首先在存储在第 k 层的一个块中查找 d. 如果 d 刚好缓存在第 k 层中, 就说是缓存命中(cache hit), 这个程序将直接从第 k 层读取 d, 加快读取的速度.
反之, 第 k 层没有缓存 d, 就说是缓存不命中(cache miss). 缓存不命中有几种原因: 空缓存导致的冷不命中, 放置策略导致的冲突不命中(如不同对象总是映射同一个数据块), 工作集大小超过缓存(如数组数量太大)导致的容量不命中.
发生缓存不命中时, 第 k 层的缓存从第 k+1 层缓存中取出包含 d 的块. 怎么放置这个块, 有不同的处理策略. 第 k 层放置好这个块以后, 程序就能像前面一样从第 k 层读出 d 了.
看到这里就会明白, 程序倾向于局部性的原因: 良好的局部性程序更容易缓存命中.
4. 高速缓存存储器¶
4.1 缓存读写¶
下面我们进一步介绍缓存的概念. 早期的存储器层次结构只有三层: CPU 寄存器, DRAM 主存和磁盘. 后来 CPU 和主存之间的速度差距逐渐增大, 又在 CPU 寄存器和主存间插入了一级到多级的 SRAM 高速缓存存储器. 下面考虑只有一级缓存: L1 高速缓存.
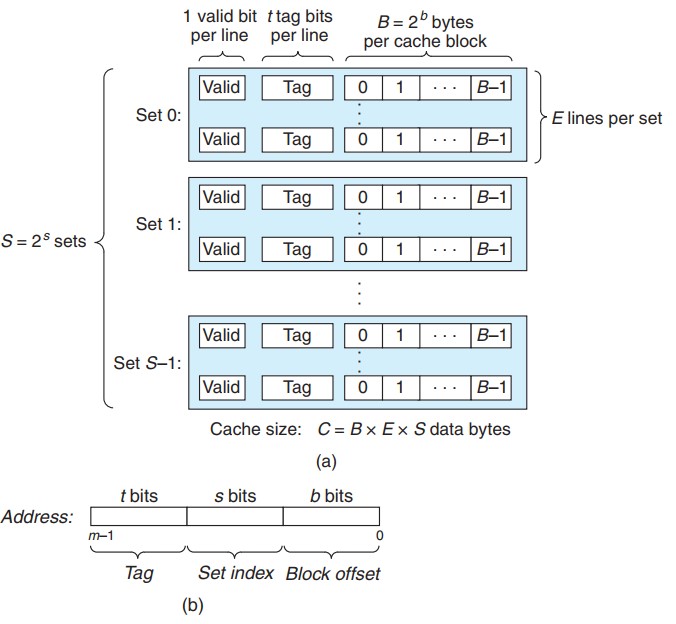
假设我们考虑的计算机系统的地址是 m 位的, 它的缓存被分为 S 组(cache set). 每个组包含 E 个高速缓存行(cache line), 每一行由一个 B 字节的数据块(block)组成. 每行有一个有效位来表示它是否有效, t 个标记位来唯一标识此行中的块.
不考虑有效位和标记位, 高速缓存的大小 C=S*E*B.
一条加载指令指示 CPU 从主存地址 A 读一个字的时候, 地址 A 被发送到高速缓存. 而高速缓存只需简单的检查地址位, 就可以确定是否有缓存有地址 A 的数据. 参数 S 和 B 可以将 A 的 m 个地址位分成三个字段. s 个组索引位是一个到 S 个组的数组索引, 被解释为一个无符号整数, 告诉我们这个字必须存储在哪个组中. t 个标记位告诉我们这个组的哪一行包括这个字. 只有这一行设置了有效位并且标记位和地址中的标记位相匹配时, 组中的这一行才包括这个字. 最后 b 个块偏移位表示在这个字在这行的数据块中的偏移.
若有 S 组, 那么只需 s=logS 位就可以表示所有组的索引; 同理, 只需 b=logB 位就可以表示所有的字的偏移. 最后, 标记位的位数就是 t=m-(s+b) 了.
至于高速缓存的不同分类, 只是将数据块按不同的方法分组罢了, 本质上大同小异, 包括直接映射高速缓存(E=1), 组相连高速缓存(1<E<C/B), 全相联高速缓存(E=C/B, S=1)三种方法, 寻址的过程已在上面介绍了.
前面介绍了读, 写的情况要复杂一些, 有直写法和写回法两种方式. 不多说.
4.2 一些指标¶
- 不命中率/命中率: 内存引用未命中/命中的比率
- 命中时间: 从高速缓存传输一个字到 CPU 所需的时间
- 不命中触发: 由于不命中所需的额外的时间.