操作系统¶
介绍¶
开始学操作系统. 学习的课程是 MIT 的 6.1810(即之前的 6.S081). 使用的教材是 OSTEP 和 xv6-book
由于是每节课一个实验, 那么我就把学习的笔记和实验记录在一起好了. 格外重要的需要详细讲的知识点, 再单独列出.
网上关于这门课的资料真的多,好好利用,网红课啊。
make qemu 运行 qemu
Ctrl-a x 退出
git 配置¶
在实验之前, 最好根据这个链接来配置你的 git: https://xv6.dgs.zone/labs/use_git/git1.html, 因为有些坑和之前的不同。
整理一下,就是先 git remote add github <your-url> 添加自己仓库的链接为 github 分支。
然后 MIT 那边的远程链接叫 origin,自己的仓库的远程链接叫 github,那么要做新实验 xxx 时:
就可以在自己的仓库新建立一个 xxx 分支。每次想要上传作业到远程仓库时,git push github xxx 即可。git checkout yyy 可以去到之前完成的作业的分支。
gdb 配置¶
调试 xv6,自然是使用 gdb 了。但是,用 gdb 的过程中,碰到了一些坑,导致我配了一下午环境才好。首先,不要使用 gdb-multiarch,感觉问题很多,自己调试的时候碰到一系列莫名其妙的问题,比如执行 ecall 指令后不会跳转到中断向量,而是直接到 ecall 的下一条物理指令。最好用 riscv64-unknown-elf-gdb 来进行调试,感觉这个的表现比较正常。但是安装又有点麻烦。
下载解压安装 gdb 的步骤看下面这个链接:
https://rcore-os.cn/rCore-Tutorial-deploy/docs/pre-lab/gdb.html
然后如果告诉你缺 GMP、MPFR 和 MPC 这三个包,照下面的链接安装这些包:
https://blog.csdn.net/weixin_38184741/article/details/107682135
这样安装好以后,就可以使用 riscv64-unknown-elf-gdb 了。调试的方法就是开两个窗口,一个运行 make qemu-gdb,一个运行 riscv64-unknown-elf-gdb。
然后之前我还大费周章地思考如何调试用户程序,其实很简单,由于 xv6 编译时贴心地给上了反汇编的结果,直接在反汇编的结果找到目标函数的虚拟地址,断点打在这个地址上就行了,例如:b *0xee。当然自己稍微注意一下,可能运行了好几个程序,对应同样的虚拟地址,所以运行到断点处未必是你之前断的地方,而是另一个程序。
而拿 ls 函数举例,我之前找到的解决方法是:
在打开以后,如果要调试 ls 函数,首先 file user/_ls 加载 elf 文件,再 b ls 即可。
注意,查看 .gdbinit 文件,可以发现默认加载 kernel/kernel 这个 elf 文件,所以调试时,内核中的 c 代码可以直接查看;而如果要调试时查看用户程序的 c 代码,就要像上面一样用 file 指令加载一下,否则就只能汇编级别的调试。
看看教授的调试吧,有所收获:
【【操作系统工程】精译【MIT 公开课 MIT6.S081】】
关于 qemu, <C-a> c 打开 qemu 的控制台,输入 info mem 可以查看页表。
Lab1: Utilities¶
这个实验主要是要熟悉一些操作系统的接口. xv6 的接口是模仿 unix 的接口的.
一些重要的接口有 fork,exec,pipe 等等。值得一提的是注意管道机制是阻塞的:只有读取端读取了数据以后,写入端才能写入新的数据。这是做 prime 实验的关键。
make qemu 打开 xv6 操作系统
<C-a> x 退出
./grade-lab-xxx abc 对 abc 进行测试。没参数批改整个实验
Lab2: Syscall¶
很简单,就是 GDB 的使用以及一些系统调用的添加。值得一提的是知道了 xv6 中的内存分配(kalloc 和 free)是通过链表实现的。
GDB 有些坑,我在开头解释。
Lab3: Pgtbl¶
这是一个关于虚拟内存的实验。糟糕的是,目前我没有什么头绪。主要是不知道代码的结构,得仔细看。
首先搞清楚操作系统给进程分配页的过程。在 proc.c 中。有三道题,第一题的工作是在进程的页表中添加一个新的页映射到虚拟地址 USYSCALL 对应的内存,直接储存 pid 等数据,这样用户端就可以从虚拟地址 USYSCALL 直接读取信息,就可以减少系统调用的次数,增加运行效率。这道题的代码都是在内核代码中修改的,所以必须仔细地阅读内核代码才能做出来。(做法是仿照 proc.c 中的做法分配和释放一个新的页,如 trapframe。一开始忘记了页的释放过程,而导致 bug)。
第二道题是打印页表。关键是如何遍历整个 PTE?
首先要知道 xv6 使用的页表结构是 riscv 的 sv39 三级页表。原理和前面学过的 Sv32 是一样的。这里我们用 64 位数据表示地址,结构如下图所示:

三级页表的转换过程如下图所示:
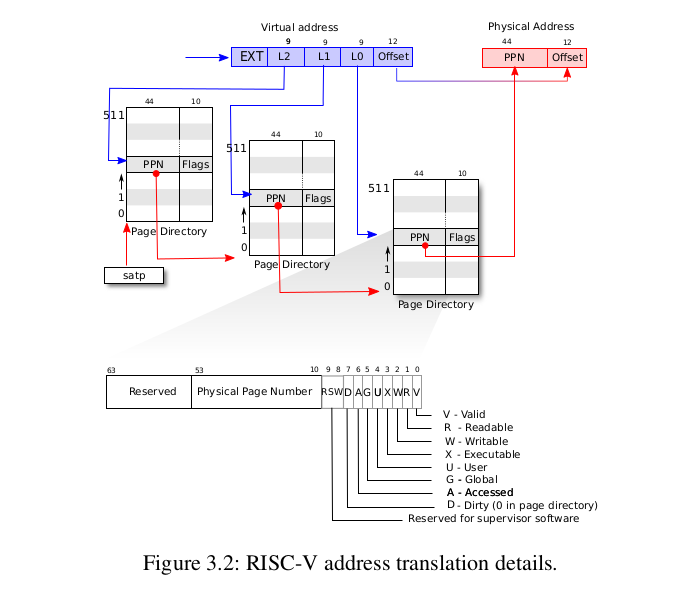
虚拟地址都是 9 位,因此每一级页表的页表项个数为 2 的 9 次方 512 个。
利用 dfs 算法,对无效的 pte 剪枝,就可以轻松地对页表项进行遍历了。
最后一题显示 hard 难度,看看什么来头。其实一点都不难。这个问题是添加一个系统调用,监测读写过的页。我觉得最难的地方是:“如何将读写过的页的页表项的对应位进行置位”。这是操作系统里做不到的,只有在 qemu 硬件上才能直接做到,因为硬件直接将虚拟地址转化为物理地址,并不经过操作系统。最后发现硬件当然是帮我们置位好了,就好像 ISA 手册描述的一样。所以这个纠结了我一天的问题的答案是,我什么也不用做。
这倒是给了我一个经验:硬件的行为是和 ISA 手册描述一致的。
还有就是位运算时可能容易犯的错了。清零用与运算,置位用或运算。
最后有一个 usertest 的测试似乎通不过,但是本次的任务基本和页表的结构等没什么关系,我就不管了。
哎,自己好没耐心啊,失去了分析的能力。问题是:“FAILED -- lost some free pages 25902 (out of 32457)” 那么显然是有一些页没有释放了,其实就是第一题里面定义的页表在结束没有释放内存:
另外,PA 的实践收获还是挺大的,因为想不起来过程了可以看自己的代码回忆。
Lab4: Trap¶
第一题打印函数调用的 backtrace,看下图清晰:
.
+-> .
| +-----------------+ |
| | return address | |
| | previous fp ------+
| | saved registers |
| | local variables |
| | ... | <-+
| +-----------------+ |
| | return address | |
+------ previous fp | |
| saved registers | |
| local variables | |
+-> | ... | |
| +-----------------+ |
| | return address | |
| | previous fp ------+
| | saved registers |
| | local variables |
| | ... | <-+
| +-----------------+ |
| | return address | |
+------ previous fp | |
| saved registers | |
| local variables | |
$fp --> | ... | |
+-----------------+ |
| return address | |
| previous fp ------+
| saved registers |
$sp --> | local variables |
+-----------------+
原理就是在没有参数寄存器的情况下,栈帧寄存器(FP/s0/x8)指向的地址,其加 8 的地址储存返回地址,加 16 储存了上一个栈帧的位置。我们只要读取出函数返回地址就可以了。
回忆一下学 x86 时的函数调用:
原理如出一辙。bp 是帧寄存器。
TODO: 在 sys_sleep() 内核函数中调用 backtrace,为什么可以一路回溯到用户程序呢?因为照理说,用的是不同的栈。
前面三个地址是内核函数,最后一个地址是用户函数。
思考一下应该和栈切换时保存的机制有关系。
第二题添加一个 alarm 系统调用,相当有难度。要实现每隔 n 个时钟中断,打印用户的 alarm 语句。碰到的困难是,需要在内核态中(时钟中断时)调用用户函数,这应该怎么实现?首先直接修改 satp 的值显然不行。因为就算切换到用户页表,寄存器的值也不同。题目给的思路是,首先将该函数的地址赋值到 sepc 中,这样到时候就直接返回到这个用户函数。然后在这个用户函数中,再使用一个系统调用切换到内核态,恢复调用该函数前的内核状态执行,然后再返回到原来的过程。
题目指导很详细,按着一步步做即可,思路就这个思路,内核代码看懂后实现挺顺利的。
Lab5: Copy-on-Write Fork¶
一开始的写法很乱,应该记得用函数封装的,还有一页内存泄露,感觉很难排查了,计划重新写一遍了。
另外,要异常重视异常情况的处理。
这个实验有难度,做完看看老师是怎么思考的,会很有收获:【MIT 6.S081 2020 操作系统 [中英文字幕]】
实际上实现的就是一种节省内存的 fork,在复制时,先让子进程的 PTE 指向父进程的物理地址,将父子可写的页都标为只读。在需要对页进行写操作时,会触发 page fault,这时再分配新的页面。而原来只读的页面,就永远父子共享了。
实现的细节已经在作业网站里有了。这里作为复习和表达的练习,再说一下吧。
首先,第一步在 uvmcopy() 函数中,修改逻辑,原先是子进程直接复制父进程的内容,现在要让子进程的虚拟地址指向父进程的物理地址。并且由于父子进程共用一份物理地址,所以应当将这里的 pte 的写权限清除。可以在 pte 中增加一个 PTE_C 标志,表示这是共用页,会很方便。
第二步,硬件如果试图写入没有读权限的页面,就会产生 page fault。这个时候就要判断是该页面是共享的页面还是只读的(看 PTE_C 有没有设置是最简单的)。如果是只读的,就抛出异常终止;反之,就为这个页面的虚拟地址分配新的物理页,让它指向新的物理页。
第三步,何时释放页面,引入一个数组,计数有多少个虚拟地址映射到对应的页面中。如果页面的映射为 0,就可以释放。比如上面,uvmcopy() 中新进程指向页面,映射数加一;trap() 中虚拟地址指向新页面,老页面的映射数减 1。
调用一次 kalloc(),将物理地址的映射初始化为 1。
修改 kfree() 的逻辑,调用时,物理地址的映射数减 1,然后看映射数,如果映射数为 0,没有虚拟地址指向这里,就可以释放这页空间。
在第一步和第二步中,添加计数的功能,如第二步中,指向新的物理页后,直接调用 kfree() 即可。
这些做完后,就差不多了,有一个 copyout() 函数也要增加一个类似的缺页异常处理,这个藏的很隐蔽。如果没有通过 cowtest 的 filetest,往上找是 pipe() 的问题,然后 pipe() 调用了 copyout() 函数。
Lab6: Multithreading¶
switching between threads in a user-level threads package.
第一题是实现了在用户态的线程切换。思路很简单,储存切换前线程的上下文在自己定义的结构中,指针为 a0(thread_switch(old, new),寄存器 a0 a1 是函数的两个参数),从 a1 中储存的地址加载寄存器,函数的返回地址放在 ra 中,当我执行 thread_switch(old, new) 的ret,就将 ra 中的值放到 pc 里面,就成功切换到了新线程。
如果是新创建的线程,将 ra 的值指向函数入口就行了。
这和内核态线程切换的区别是,不涉及任何从用户态陷入内核态的过程,很方便。